作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/cfb848a15208557d/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
文本接上篇:EM算法和混合模型一:EM算法,来谈谈EM算法具体应用:混合模型。
二、一般混合模型问题
2.1、问题描述
考虑一随机变量的离散混合情况。这句话意思是说:观测到的随机变量可能是由离散可数个分布中的一个产生的:
$$\begin{align}
\bm{x}\sim \sum_{k=1}^K \pi_k \times p\big(\bm{x}\mid \bm{\theta}_k\big)
\end{align}$$
例如:
$$\begin{align}
p(x)=0.35\times\mathcal{N}\big(x\mid 5,25\big)+0.25\times\mathcal{N}\big(x\mid 15,9\big)+0.4\times\mathcal{N}\big(x\mid -10,25\big)
\end{align}$$
2.2、引入隐变量(Latent variables)
考虑一般混合模型的数据集 $\displaystyle \mathcal{D}^\bm{x}=\{\bm{x}_i\}_{i=1}^N$,我们加入隐含变量 $\displaystyle \bm{z}\in\{0,1\}^K=\mathcal{C}$、$\displaystyle \bm{I}^\text{T}\bm{z}=1$、 $\displaystyle N_k=\sum_{i=1}^{N}z_{ik}$、 $\displaystyle \bm{N}_k=[N_1,…,N_k,…,N_K]^\text{T}$。这是我们在分类分布 $\displaystyle \mathrm{Cat}$中,惯用的方法: $\displaystyle \textit{1 of K}$编码方法。这样我们有完整数据集:$\displaystyle \mathcal{D}^{+}=\{\bm{x}_i,\bm{z}_i\}_{i=1}^N$,同时我们把 $\displaystyle \mathcal{D}^\bm{x}$称为不完整数据集。
2.3、隐变量先验分布与 $\displaystyle \bm{x}$的条件分布
显然:
$$\begin{align}
p\big(\bm{z}\mid \bm{\pi}\big)
=\mathrm{Cat}\big(\bm{z}\mid \bm{\pi}\big)
=\prod_{k=1}^K\pi_k^{z_k}
\end{align}$$这个分布我们称之为 $\displaystyle \bm{z}$的先验分布,同时我们还有 $\displaystyle \bm{x}$的条件概率分布:
$$\begin{align}
p \big(\bm{x}\mid \bm{z},\bm{\theta}\big)=\prod_{k=1}^Kp\big(\bm{x}\mid \bm{\theta}_k\big)^{z_k}
\end{align}$$
2.4、隐变量与观测变量的联合分布导出观测变量分布
注意到: $\displaystyle \bm{z}\in\{0,1\}^K=\mathcal{C}$。这时的混合模型为:
$$\begin{align}
p(\bm{x}\mid \bm{\theta},\bm{\pi})
&=\sum_{\bm{z}\in \mathcal{C}}p\big(\bm{x},\bm{z}\mid\bm{\theta},\bm{\pi}\big)
=\sum_{\bm{z}\in \mathcal{C}}p\big(\bm{z}\mid \bm{\pi}\big)p\big(\bm{x}\mid \bm{z},\bm{\theta}\big)\\
&=\sum_{\bm{z}\in \mathcal{C}}\bigg[\mathrm{Cat}\big(\bm{z}\mid \bm{\pi}\big)\times\prod_{k=1}^Kp\big(\bm{x}\mid \bm{\theta}_k\big)^{z_k}\bigg]\\
\end{align}$$$$\begin{align}
&=\sum_{\bm{z}\in \mathcal{C}}\bigg[\prod_{k=1}^K\pi_k^{z_k}\times\prod_{k=1}^Kp\big(\bm{x}\mid \bm{\theta}_k\big)^{z_k}\bigg]\\
&=\sum_{\bm{z}\in \mathcal{C}}\bigg[\prod_{k=1}^K\big[\pi_k^{z_k}p\big(\bm{x}\mid \bm{\theta}_k\big)^{z_k}\big]\bigg]\\
&=\sum_{k=1}^K\pi_kp\big(\bm{x}\mid \bm{\theta}_k\big)
\end{align}$$这是隐变量的经典变换技巧,请务必熟悉 $\displaystyle D、K、N$与 $\displaystyle d、k、i$的下标翻译。
上述推导中,我们有 隐变量与观测变量的联合分布:
$$\begin{align}
p\big(\bm{x},\bm{z}\mid\bm{\theta},\bm{\pi}\big)=p\big(\bm{z}\mid \bm{\pi}\big)p\big(\bm{x}\mid \bm{z},\bm{\theta}\big)=\prod_{k=1}^K\big[\pi_k^{z_k}p\big(\bm{x}\mid \bm{\theta}_k\big)^{z_k}\big]
\end{align}$$
2.5、隐变量后验概率分布与期望
现在我们来考察后验概率分布 $\displaystyle p\big(\bm{z}\mid \bm{x},\bm{\mu},\bm{\pi}\big)=\frac{p\big(\bm{x},\bm{z}\mid \bm{\mu},\bm{\pi}\big)}{p\big(\bm{x}\mid \bm{\mu},\bm{\pi}\big)}=\frac{p\big(\bm{x},\bm{z}\mid \bm{\mu},\bm{\pi}\big)}{\displaystyle\sum_{\bm{z}\in\mathcal{C}}p\big(\bm{x},\bm{z}\mid \bm{\mu},\bm{\pi}\big)}$
$$\begin{align}
q\big(\bm{z}\mid \bm{x},\bm{\mu},\bm{\pi}\big)=\frac{\displaystyle\prod_{k=1}^K\big[\pi_k^{z_k}p\big(\bm{x}\mid \bm{\mu}_k\big)^{z_k}\big]}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}\mid \bm{\mu}_k\big)}
\end{align}$$
注意到 $\displaystyle z_{ik}\in\{0,1\}$,下式
$\displaystyle
\mathrm{E}[z_{ik}]
=\sum_{z_{ik}}\big[\bm{I}^\text{T}\bm{z}_i\times q\big(\bm{z}_i\mid \bm{x},\bm{\theta},\bm{\pi}\big)\big]
=\frac{\displaystyle\sum_{\bm{z}}z_{ik}\prod_{k=1}^K\big[\pi_k^{z_{ik}}p\big(\bm{x}_i\mid \bm{\theta}_k\big)^{z_{ik}}\big]}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}
=\frac{\displaystyle\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}
$
2.6、完全数据集对数似然函数期望
我们将反复使用独立分布数据集的可分解性质。这就是为什么我们可以移动期望符号 $\displaystyle \mathrm{E}$的原因。
$$\begin{align}
\mathrm{E}\big[
\ell \big(\mathcal{D}^+\mid \bm{\theta},\bm{\pi}\big)\big]
&=\mathrm{E}\bigg[\sum_{i=1}^N\ln p\big(\bm{x}_i,\bm{z}_i\mid \bm{\theta},\bm{\pi}\big)\bigg]\\
&=\sum_{i=1}^N \bigg[\mathrm{E}\big[\ln p\big(\bm{x}_i,\bm{z}_i\mid \bm{\theta},\bm{\pi}\big)\big]\bigg]\\
&=\sum_{i=1}^N \left[\mathrm{E}\bigg[\ln p \big(\bm{z}_i\mid \bm{\pi}\big)+\ln p \big(\bm{x}_i\mid \bm{z}_i,\bm{\theta}\big)\bigg]\right]\\
\end{align}$$将模型代入,于是有:$$\begin{align}
\mathrm{E}\big[
\ell \big(\mathcal{D}^+\mid \bm{\theta},\bm{\pi}\big)\big]
&=\sum_{i=1}^N\sum_{k=1}^K \mathrm{E}\left[z_{ik}\bigg[\ln \pi_k+\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\bigg]\right]\\
&=\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\big[\ln \pi_k+\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\big]\bigg]\\
&=\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln \pi_k\bigg]+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\bigg]\\
\end{align}$$
2.7、混合模型EM算法中隐变量的参数估计
令 $\displaystyle \mathrm{E}_{\mathcal{D}^+}=\mathrm{E}\big[
\ell \big(\mathcal{D}^+\mid \bm{\theta},\bm{\pi}\big)\big]$,于是我们有:
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\bigg]
\end{align}$$现在考虑 $\displaystyle \bm{\pi}$,知道 $\displaystyle \bm{I}^\text{T}\bm{\pi}=1$
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}
&\propto \bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln \bm{\pi}+\lambda\big[\bm{I}^\text{T}\bm{\pi}-1\big]
\end{align}$$于是有
$$\begin{cases}
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \bm{\pi}}&\displaystyle=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{\bm{\pi}}+\lambda\bm{I}=\bm{0}\\
\\
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \lambda}&\displaystyle=\bm{I}^\text{T}\bm{\pi}-1=0
\end{cases}$$
分析可得 $\displaystyle \bm{\pi}_{EM}=-\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{\lambda} $ 代入 $\displaystyle \bm{I}^\text{T}\bm{\pi}-1=0$得: $\displaystyle \frac{\bm{I}^\text{T}\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{\lambda}=-1$由于 $\displaystyle \bm{I}^\text{T}\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}=N$,同时令 $\displaystyle \bm{N}_k=\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}$可得:
$$\begin{align}
\begin{cases}
\displaystyle\lambda=-N\\
\\
\displaystyle\bm{\pi}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{N}=\frac{\bm{N}_k}{N}
\end{cases}
\end{align}$$
其中: 我们有 $\displaystyle \sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]=1$,于是 $\displaystyle \bm{I}^\text{T}\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}=\bm{I^\text{T}I}=N$,在混合模型中 $\displaystyle\bm{\pi}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{N}=\frac{\bm{N}_k}{N}$ 的结论是通用的。
三、伯努利混合模型
3.1、伯努利分布混合模型表述
考虑一个 $\displaystyle D$ 维二值变量 $\displaystyle \bm{x}$ 的密度是如下密度的混合:
$$\begin{align}
p(\bm{x}\mid \bm{\mu})=\prod_{d=1}^D\mathrm{Ber}\big(x_d\mid \mu_d\big)=\prod_{d=1}^D\mu_d^{x_d}\big(1-\mu_d\big)^{1-x_d}
\end{align}$$也就是有:
$$\begin{align}
p(\bm{x}\mid \bm{\mu},\bm{\pi})=\sum_{k=1}^K\pi_kp\big(\bm{x}\mid \bm{\mu}_k\big)=\sum_{k=1}^K\Bigg[\pi_k\prod_{d=1}^D\mu_{kd}^{x_d}\big(1-\mu_{kd}\big)^{1-x_d}\Bigg]
\end{align}$$
3.2、伯努利混合模型完全数据集对数似然函数期望
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}
&=\sum_{i=1}^N\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\bigg[\ln \pi_k+\sum_{d=1}^D\big[x_{id}\ln\mu_{kd}+\big(1-x_{id}\big)\ln\big(1-\mu_{kd}\big)\big]\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \Bigg[\mathrm{E}\big[z_{ik}\big]\bigg[\bm{x}_{i}^\text{T}\ln\bm{\mu}_{k}+\big[\bm{I}-\bm{x}_{i}\big]^\text{T}\ln\big[\bm{I}-\bm{\mu}_{k}\big]\bigg]\Bigg]\\
\end{align}$$
3.3、最大化完全数据集对数似然函数期望:
$$\begin{align}
\max_{\bm{\pi},\bm{\theta}}\mathrm{E}\big[\ell \big(\mathcal{D}^+\mid \bm{\mu},\bm{\pi}\big)\big]
\end{align}$$
考虑 $\displaystyle \bm{\pi}$有
$$\begin{align}
\bm{\pi}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{N}=\frac{\bm{N}_k}{N}
\end{align}$$
现在我们考虑 $\displaystyle \bm{\mu}_k$,同时注意到 $\displaystyle \sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]=1$
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}
&\propto\sum_{i=1}^N\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\bigg[\sum_{d=1}^D\big[x_{id}\ln\mu_{kd}+\big(1-x_{id}\big)\ln\big(1-\mu_{kd}\big)\big]\bigg]\\
&=\sum_{i=1}^N\Bigg[\sum_{k=1}^K \sum_{d=1}^D\mathrm{E}\big[z_{ik}\big]\cdot\ln\mu_{kd}\cdot x_{id}+\sum_{k=1}^K \sum_{d=1}^D\mathrm{E}\big[z_{ik}\big]\cdot\ln\big(1-\mu_{kd}\big)\cdot\big(1-x_{id}\big)\bigg]\\
&=\sum_{i=1}^N\bigg[\mathrm{E}^\text{T}[\bm{z}_i]\cdot\ln[\bm{U}]\cdot \bm{x}_i+\mathrm{E}^\text{T}[\bm{z}_i]\cdot\ln[\bm{I}-\bm{U}]\cdot[\bm{I}-\bm{x}_i]\bigg]\\
&=\mathrm{tr}\bigg(\mathrm{E}\big[\bm{Z}\big]\cdot\ln\big[\bm{U}\big]\cdot \bm{X}^\text{T}\bigg)+\mathrm{tr}\bigg(\mathrm{E}\big[\bm{Z}\big]\cdot\ln\big[\bm{I}-\bm{U}\big]\cdot \big[\bm{I}-\bm{X}\big]^\text{T}\bigg)
\end{align}$$
有:
$$\begin{align}
\frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \bm{U}}
=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\bm{U}}-\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\big[\bm{I}-\bm{X}\big]}{\bm{I}-\bm{U}}=0
\end{align}$$
点除和点乘运算,我们写出细节,大家体会一下:
$$\begin{align}
&\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\bm{U}}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\big[\bm{I}_{N\times D}-\bm{X}\big]}{\bm{I}_{K\times D}-\bm{U}}\\
\iff&\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\odot \bm{I}-\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\odot \bm{U}=\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}\odot \bm{U}-\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\odot \bm{U}\\
\iff&\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}=\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}\odot \bm{U}\\
\iff &\bm{U}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_{N\times D}}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_N}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}
\end{align}$$
得:
$$\begin{align}
\bm{U}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\bm{N}_k}
\end{align}$$
注意:上面的除法都是点除运算。 $\displaystyle \bm{U}=[\bm{\mu}_1,\bm{\mu}_2,\cdots,\bm{\mu}_k]^\text{T}\,\bm{\mu}\in [0,1]^D$,于是我们有:
$$\begin{align}
\begin{cases}
\displaystyle\mathrm{E}[z_{ik}]=\frac{\displaystyle\pi_kp\big(\bm{x}_i\mid \bm{\mu}_k\big)}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}_i\mid \bm{\mu}_k\big)}\\
\displaystyle\bm{\pi}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{N}=\frac{\bm{N}_k}{N}\\
\displaystyle\bm{U}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}}{\bm{N}_k}
\end{cases}
\end{align}$$
3.4、伯努利混合模型EM算法
算法:伯努利混合模型EM算法
1 $\displaystyle \bm{\pi}_0=\bm{a}$
2 $\displaystyle \bm{U}_o=\bm{A}$
3 $\displaystyle \text{while }\mathrm{E}_{q^t}\big[\ell\big(\mathcal{D}^+\mid \bm{\pi}_{t+1},\bm{U}_{t+1}\big)=\text{converged}$ :
$\displaystyle
\quad\begin{array}{|lc}
\text{ E step}\\
\text{—————-}\\
\text{for i in range(1,N+1):}\\
\quad\text{for k in range(1,K+1):}\\
\quad\quad\mathrm{E}\big[z_{ik}^t\big]=\frac{\displaystyle\pi_k^tp\big(\bm{x}_i\mid \bm{\mu}_k^t\big)}{\displaystyle\sum_{k=1}^K\pi_k^tp\big(\bm{x}_i\mid \bm{\mu}_k^t\big)}\\
\quad\text{ end for k}\\
\text{ end for i}\\
\text{ M step}\\
\text{—————-}\\
\bm{U}_{t+1}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}_t\big]\bm{X}}{\mathrm{E}^\text{T}\big[\bm{Z}_t\big]\bm{I}}\\
\bm{\pi}_{t+1}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}_t\big]\bm{I}}{N}\\
\end{array}\\$
4 $\displaystyle \bm{\pi}_{end}$
5 $\displaystyle \bm{U}_{end}$
end while
3.5、伯努利混合模型简单举例
现在我们假定: $\displaystyle \mu_{k1}=\cdots=\mu_{kd}=\cdots=\mu_{kD}=\mu_k$。
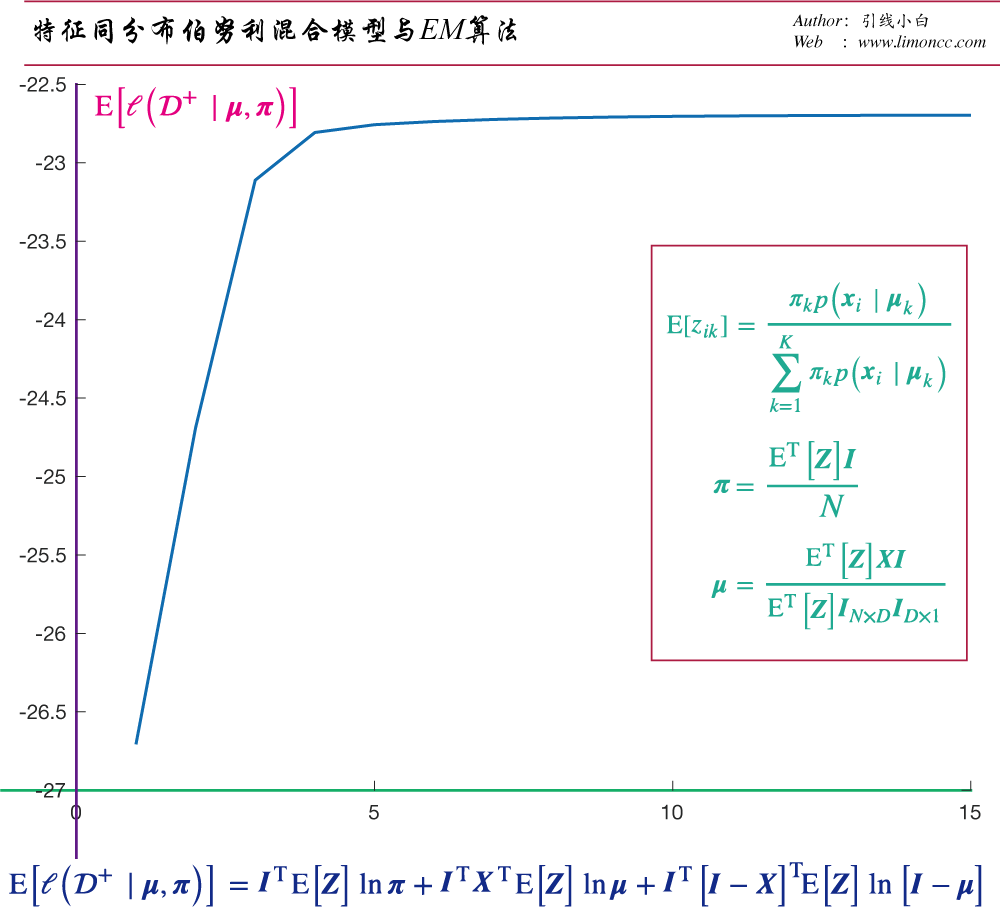
不完全模型
它的故事是这样的:上帝有两个硬币A、B:这两个硬币抛出正面的概率分别是0.75和0.25。上帝每次抛硬币都以一定概率来选择A或B,一旦选出,上帝会抛七次。结果上帝选了5次硬币,同时抛了 $\displaystyle 5\times7$次。现在我们仅仅通过$\displaystyle 5\times7$次中,我们观察到的正反来猜测上帝硬币的概率:我们就有特征同分布、伯努利混合模型的完全数据集:它对数似然函数的期望。
$$\begin{align}
\mathrm{E}\big[\ell \big(\mathcal{D}^+\mid \bm{\mu},\bm{\pi}\big)\big]=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\bm{I}^\text{T}\bm{X}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\mu}
+\bm{I}^\text{T}\big[\bm{I}-\bm{X}\big]^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\big[\bm{I}-\bm{\mu}\big]
\end{align}$$
证明:
$$\begin{align}
&\mathrm{E}_{\mathcal{D}^+}=\mathrm{E}\big[\ell \big(\mathcal{D}^+\mid \bm{\mu},\bm{\pi}\big)\big]\\
&=\sum_{i=1}^N\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\bigg[\ln \pi_k+\sum_{d=1}^D\big[x_{id}\ln\mu_{kd}+\big(1-x_{id}\big)\ln\big(1-\mu_{kd}\big)\big]\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\sum_{i=1}^N\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\bigg[\sum_{d=1}^D\big[x_{id}\ln\mu_{kd}+\big(1-x_{id}\big)\ln\big(1-\mu_{kd}\big)\big]\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\sum_{i=1}^N\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\bigg[\big[\bm{x}_{i}^\text{T}\bm{I}\ln\mu_{k}+\big(\bm{I}-\bm{x}_{i}\big)^\text{T}\bm{I}\ln\big(1-\mu_{k}\big)\big]\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\sum_{i=1}^N\bigg[\bm{I}^\text{T}\bm{x}_{i}\cdot\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\ln\mu_{k}
+\bm{I}^\text{T}\big(\bm{I}-\bm{x}_{i}\big)\cdot\sum_{k=1}^K\mathrm{E}\big[z_{ik}\big]\ln\big(1-\mu_{k}\big)\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\sum_{i=1}^N\bigg[\bm{I}^\text{T}\bm{x}_{i}\mathrm{E}^\text{T}\big[\bm{z}_{i}\big]\ln\bm{\mu}
+\bm{I}^\text{T}\big(\bm{I}-\bm{x}_{i}\big)\mathrm{E}^\text{T}\big[\bm{z}_{i}\big]\ln\big(\bm{I}-\bm{\mu}\big)\bigg]\\
&=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}
+\bm{I}^\text{T}\bm{X}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\mu}
+\bm{I}^\text{T}\big[\bm{I}-\bm{X}\big]^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\big[\bm{I}-\bm{\mu}\big]\\
\end{align}$$
证毕。
考虑 $\displaystyle \bm{\mu}$,最大化这个期望。于是我们有
$$\begin{align}
\frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \bm{\mu}}
=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}}{\bm{\mu}}-\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\big[\bm{I}-\bm{X}\big]\bm{I}}{\bm{I}-\bm{\mu}}=0
\end{align}$$
我们来详细推导一下,以熟悉点乘、点除运算:
$$\begin{align}
&\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}_{D\times 1}}{\bm{\mu}}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\big[\bm{I}_{N\times D}-\bm{X}\big]\bm{I}_{D\times1}}{\bm{I}_{K\times 1}-\bm{\mu}}\\
&\iff\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}\odot \bm{I}-\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}\odot \bm{\mu}=\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_{N\times D}\bm{I}\odot \bm{\mu}-\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}\odot \bm{\mu}\\
&\iff\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}=\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_{N\times D}\bm{I}_{D\times1}\odot \bm{\mu}\\
&\iff \bm{\mu}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_{N\times D}\bm{I}_{D\times1}}
=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}_{N\times I}D}
=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{X}\bm{I}}{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}D}
\end{align}$$
3.6、伯努利混合模型EM算法图示
现在我开始开头的那个例子,用图示画出来:
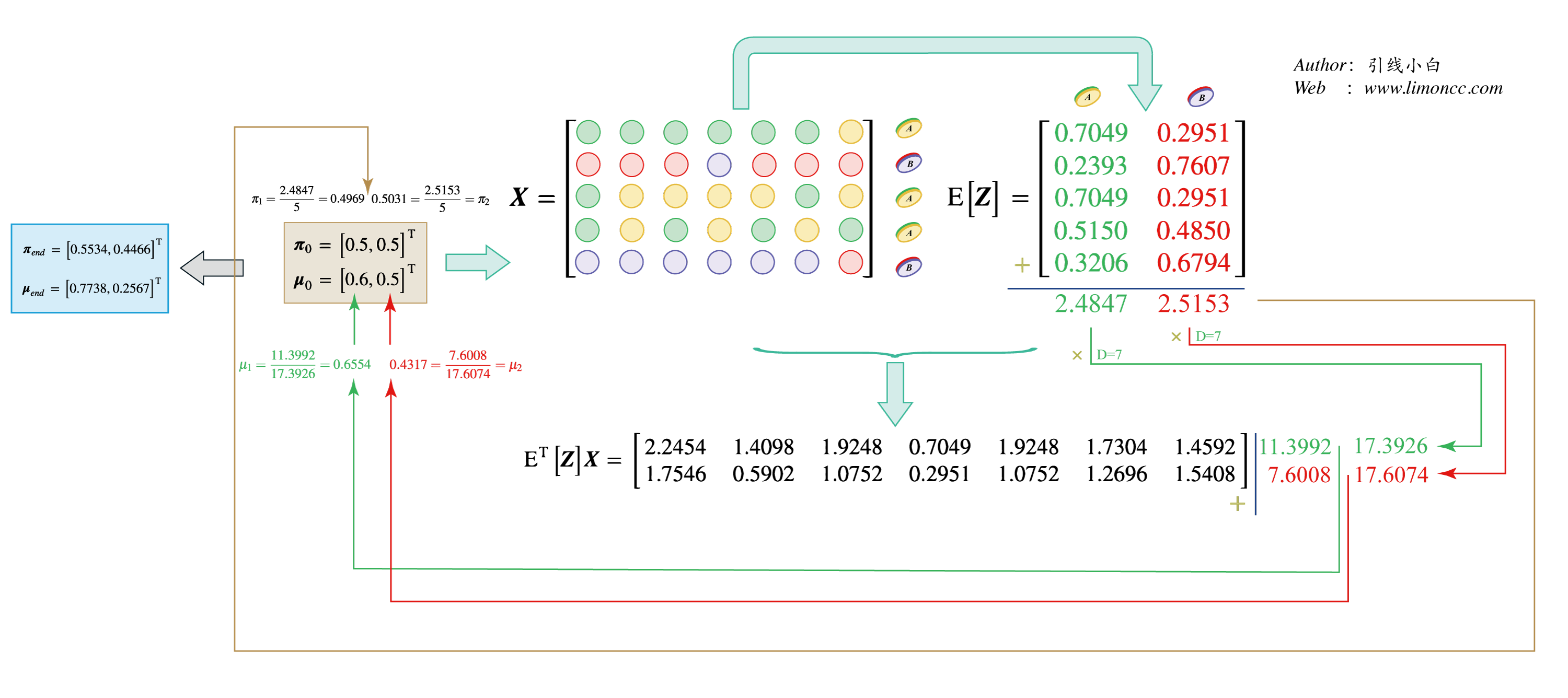
EM算法实例
四、高斯混合模型
4.1、高斯混合模型问题描述
$$\begin{align}
\bm{x}\sim \sum_{k=1}^K \bm{\pi}_k \mathcal{N}\big(\bm{x}\mid \bm{\mu}_k,\bm{C}_k\big)
\end{align}$$
4.2、高斯混合模型完全数据集对数似然函数期望
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln \mathcal{N}\big(\bm{x}\mid \bm{\mu}_k,\bm{C}_k\big)\bigg]
\end{align}$$
4.3、最大化完全数据集对数似然函数期望
现在我们开始适当的变形,以期取得关于 $\displaystyle \bm{\mu}_k$、 $\displaystyle \bm{C}_k$的恰当形式。
$$\begin{align}
&\mathrm{E}_{\mathcal{D}^+}=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln \mathcal{N}\big(\bm{x}\mid \bm{\mu}_k,\bm{C}_k\big)\bigg]\\
&\propto\sum_{k=1}^K\Bigg[\sum_{i=1}^N \mathrm{E}\big[z_{ik}\big]\bigg[-\frac{k}{2}\ln 2\pi+\frac{1}{2}\ln\big|\bm{\Lambda}_k\big|-\frac{1}{2}\big[\bm{x}_i- \bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\big[\bm{x}_i- \bm{\mu}_k\big]\bigg]\Bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\bigg[-k\times\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln 2\pi+\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\sum_{i=1}^N\mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i- \bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\big[\bm{x}_i- \bm{\mu}_k\big]\bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\sum_{i=1}^N\mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i- \bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\big[\bm{x}_i- \bm{\mu}_k\big]\bigg]\\
\end{align}$$进而有:
$$\begin{align}
&\mathrm{E}_{\mathcal{D}^+}=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln \mathcal{N}\big(\bm{x}\mid \bm{\mu}_k,\bm{C}_k\big)\bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\mathrm{tr}\bigg(\sum_{i=1}^N\mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i- \bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\big[\bm{x}_i- \bm{\mu}_k\big]\bigg)\bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|- \mathrm{tr}\bigg(\sum_{i=1}^N\mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i- \bm{\mu}_k\big]\big[\bm{x}_i- \bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\bigg)\bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\mathrm{tr}\bigg(\mathrm{E}^\text{T}\big[\bm{z}_k\big]\odot\big[\bm{X}- \bm{M}_k\big]^\text{T}\big[\bm{X}- \bm{M}_k\big]\bm{\Lambda}_k\bigg)\bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\Bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\mathrm{tr}\bigg(\mathrm{E}^\text{T}\big[\bm{z}_k\big]\odot \bm{S}_{\bm{\mu}_k}\bm{\Lambda}_k\bigg)\Bigg]
\end{align}$$
4.4、高斯混合模型EM算法
1、关于 $\displaystyle \mathrm{E}\big[\bm{Z}\big]$
$$\begin{align}
\mathrm{E}\big[z_{ik}\big]=\frac{\displaystyle\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}=\frac{\displaystyle\pi_k \mathcal{N}\big(\bm{x}_i\mid \bm{\mu}_k,\bm{C}_k\big)}{\displaystyle\sum_{k=1}^K\pi_k\mathcal{N}\big(\bm{x}_i\mid \bm{\mu}_k,\bm{C}_k\big)}
\end{align}$$
2、关于 $\displaystyle \bm{\pi}$有:
$$\begin{align}
\bm{\pi}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{\bm{I}^\text{T}\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}=\frac{\bm{N}_k}{N}
\end{align}$$
3、关于 $\displaystyle \bm{\mu}_k,\bm{C}_k$
$$\begin{align}
\mathrm{E}_{\mathcal{D}^+}
&\propto \frac{1}{2}\sum_{k=1}^K\Bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\sum_{i=1}^N \mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i-\bm{\mu}_k\big]^\text{T}\bm{\Lambda}_k\big[\bm{x}_i- \bm{\mu}_k\big]\Bigg]\\
&\propto \frac{1}{2}\sum_{k=1}^K\Bigg[\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big|\bm{\Lambda}_k\big|-\mathrm{tr}\bigg(\mathrm{E}^\text{T}\big[\bm{z}_k\big]\odot \bm{S}_{\bm{\mu}_k}\bm{\Lambda}_k\bigg)\Bigg]
\end{align}$$
于是我们有:
$$\begin{align}
\begin{cases}
\displaystyle \frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \bm{\mu}_k}=\frac{1}{2}\big[\bm{\Lambda}_k+\bm{\Lambda}^\text{T}_k\big]\sum_{i=1}^N\bigg[ \mathrm{E}\big[z_{ik}\big]\big[\bm{x}_i- \bm{\mu}_k\big]\bigg]=\bm{X}^\text{T}\mathrm{E}\big[\bm{z}_k\big]-\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\bm{\mu}_k=0\\
\displaystyle \frac{\partial \mathrm{E}_{\mathcal{D}^+}}{\partial \bm{\Lambda}_k}=\frac{1}{2}\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\bm{\Lambda}^{-1}_k- \frac{1}{2}\mathrm{E}^\text{T}\big[\bm{z}_k\big]\odot \bm{S}_{\bm{\mu}_k}=0
\end{cases}
\end{align}$$
简单变形有:
$$\begin{align}
\begin{cases}
\displaystyle \bm{\mu}_k=\frac{\bm{X}^\text{T}\mathrm{E}\big[\bm{z}_k\big]}{\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]}\\
\\
\displaystyle \bm{C}_k=\frac{\mathrm{E}^\text{T}\big[\bm{z}_k\big]}{\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]}\odot \bm{S}_{\bm{\mu}_k}
\end{cases}
\end{align}$$
五、评述
1、EM算法的关键在于引入隐变量,然后我们考察它的先验、后验和完全数据集分布,于是我们得到: 不完全数据集对数似然函数等价变换:
$$\begin{align}
\ell \big(\mathcal{D}^\bm{x}\mid \bm{\theta}\big)=\mathrm{E}_{q}\big[\ell\big(\mathcal{D}^+\mid \bm{\theta}\big)\big]+\mathrm{H}\big[q,p\big]=\mathrm{E}_{q}\big[\ell\big(\mathcal{D}^+\mid \bm{\theta}\big)\big]+\mathrm{H}\big[q\big]+\mathrm{KL}\big[q\parallel p\big]
\end{align}$$正是因为如此,我们才有了【EM算法收敛定律】:
$$\begin{align}
\exists \,\bm{\theta}_{end}\to\max\ell \big(\mathcal{D}^\bm{x}\mid \bm{\theta}\big)\iff\max \mathrm{E}_{q}\big[\ell\big(\mathcal{D}^+\mid \bm{\theta}\big)\big]
\end{align}$$
2、一般混合模型的完全数据集分布:
$$\begin{align}
\mathrm{E}\big[
\ell \big(\mathcal{D}^+\mid \bm{\theta},\bm{\pi}\big)\big]=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}+\sum_{i=1}^N\sum_{k=1}^K \bigg[\mathrm{E}\big[z_{ik}\big]\ln p\big(\bm{x}_i\mid\bm{\theta}_k\big)\bigg]
\end{align}$$且有通用的结论:
$$\begin{align}
\begin{cases}
\displaystyle\mathrm{E}[z_{ik}]
=\frac{\displaystyle\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}{\displaystyle\sum_{k=1}^K\pi_kp\big(\bm{x}_i\mid \bm{\theta}_k\big)}\\
\\
\displaystyle\bm{\pi}_{EM}=\frac{\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}{\bm{I}^\text{T}\mathrm{E}^\text{T}\big[\bm{Z}\big]\bm{I}}=\frac{\bm{N}_k}{N}
\end{cases}
\end{align}$$
3、伯努利混合模型完全数据集对数似然函数期望
$$\begin{align}
&\mathrm{E}\big[\ell \big(\mathcal{D}^+\mid \bm{\mu},\bm{\pi}\big)\big]=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}\\
&+\mathrm{tr}\bigg(\mathrm{E}\big[\bm{Z}\big]\cdot\ln\big[\bm{U}\big]\cdot \bm{X}^\text{T}\bigg)+\mathrm{tr}\bigg(\mathrm{E}\big[\bm{Z}\big]\cdot\ln\big[\bm{I}-\bm{U}\big]\cdot \big[\bm{I}-\bm{X}\big]^\text{T}\bigg)
\end{align}$$
4、高斯混合模型完全数据集对数似然函数期望
$$\begin{align}
&\mathrm{E}\big[\ell \big(\mathcal{D}^+\mid \bm{\pi},\bm{\mu},\bm{C}\big)\big]=\bm{I}^\text{T}\mathrm{E}\big[\bm{Z}\big]\ln\bm{\pi}\\
&+ \frac{1}{2}\sum_{k=1}^K\Bigg[-k\times\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln 2\pi+\bm{I}^\text{T}\mathrm{E}\big[\bm{z}_k\big]\ln\big[\bm{\Lambda}_k\big]-\mathrm{tr}\bigg(\mathrm{E}^\text{T}\big[\bm{z}_k\big]\odot \bm{S}_{\bm{\mu}_k}\bm{\Lambda}_k\bigg)\Bigg]
\end{align}$$也就是说,知道了完全数据集对数似然函数期望,我们就可以递归求解了,而这就是期望最大算法EM
5、然后EM要求混合模型已知混合了多少类型: $\displaystyle k$。显然上帝不会轻易告诉我们,我们需要继续征程。
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/cfb848a15208557d/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Mar. 14, 2017). 《EM算法和混合模型二:混合模型案例》[Blog post]. Retrieved from https://www.limoncc.com/post/cfb848a15208557d |
| @online{limoncc-cfb848a15208557d, title={EM算法和混合模型二:混合模型案例}, author={引线小白}, year={2017}, month={Mar}, date={14}, url={\url{https://www.limoncc.com/post/cfb848a15208557d}}, } |