作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/7a80f1e682c4de99/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
摘要: 本文意在理清大模型使用工具原理和使用。若有错误,请大家指正。
关键词:使用工具,大模型,提示词
一、使用tool_llama来使得开源模型调用工具
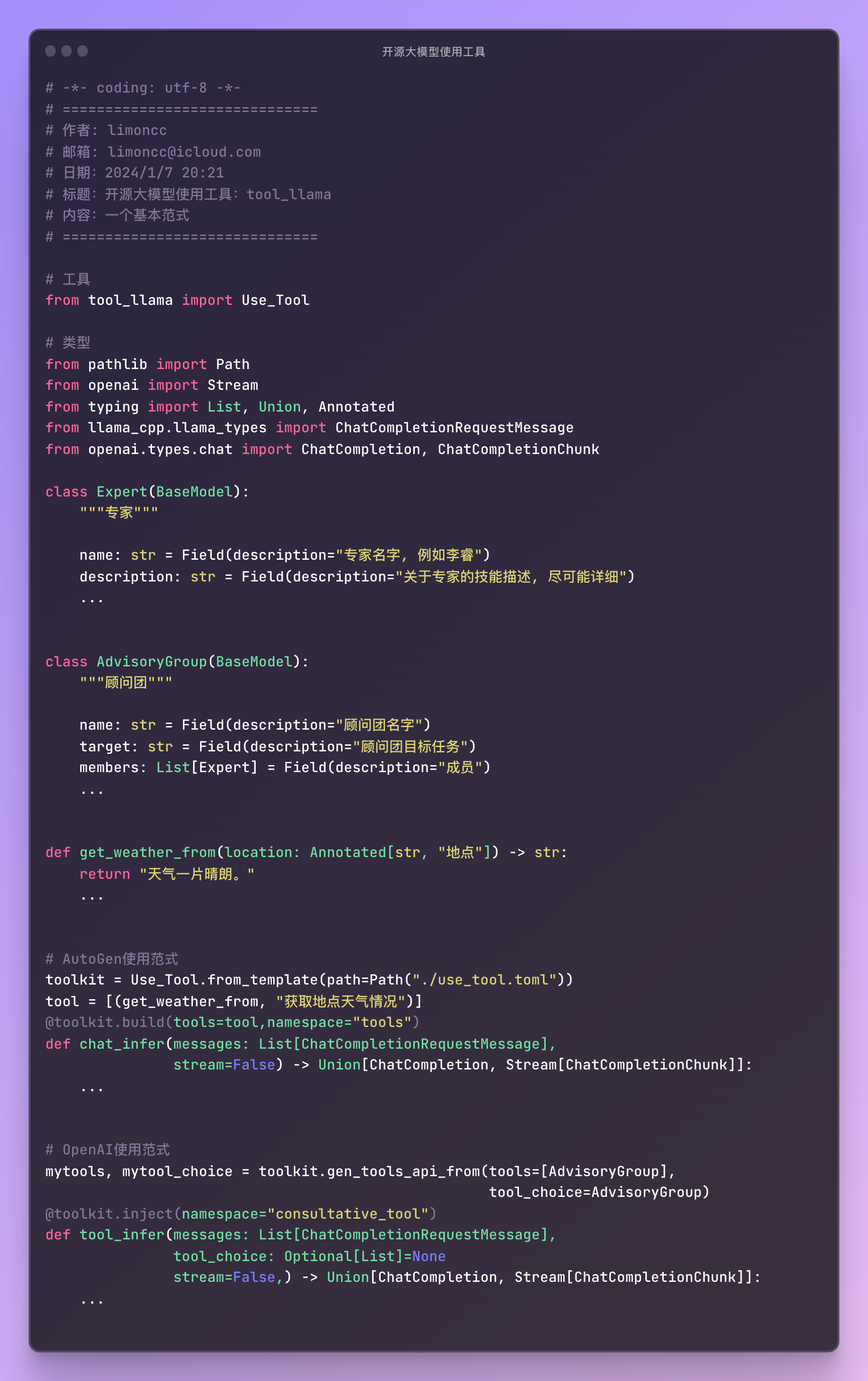
不买关子,直接上干货:tool_llama是由笔者开发的工具,它配合llama-cpp-python的模型服务使用,它有一下特点
- 1、支持pydantic风格工具输入
- 2、外部的装饰器风格导入工具与数据模型, 然后使用工具
- 3、支持llama-cpp-python通用聊天模式,不必为了使用工具启动两个模型
下面是一个极简使用方法:
1.1、安装
1 | pip install tool_llama |
然后用llama-cpp-python启动一个模型服务,如果不懂这一步可以参考网上的文字和llama-cpp-python的文档
1 | python -m llama_cpp.server \ |
1.2、AutoGen的使用模式
需要实现一个推理函数:messages,stream这个两个参数是必须的。然后你可以使用BaseModel来规范数据格式。这对与你想获得指定格式非常有用。
@toolkit.build(tools=[AdvisoryGroup], tool_choice=AdvisoryGroup, namespace=”consultative_tool”)
chat_infer(messages: List[ChatCompletionRequestMessage], stream=False)
你也可以构造一个函数工具,使用typing的类型和Annotated来注释。并使用一个元组来注释函数。
1 | # tools |
1 | {'name': 'AI Landing Application Advisory Group', |
1.3、OpenAI的使用模式
OpenAI的使用模式可以方便你构建使用工具的API,当然如果你对llama-cpp-python熟悉,你也可以构造一个通用的chat-dformat,支持使用API调用工具。tool_llama作为一个独立包尽量解耦。如何魔改llama-cpp-python,笔者将在一下篇文章中介绍。
1 | # openai model |
1.4、OpenAI的使用模式不使用工具
当然如果你不使用工具,不输入tools变量即可使正常聊天的模式。
1 | response = tool_infer(msg, stream=True) |
1 | To create an effective team of advisors for solving the AI landing application problem, we need to consider individuals with diverse expertise and skill sets. Here's a suggested team comprising three experts: |
二、原理探索
大模型使用工具并不是新鲜事情。OpenAI已经在其接口中包含了工具的使用参数。这里不再叙述。
有好事者在OpenAI社区使用如下提示词,对GPT4使用工具的prompt进行了逆向工程:
1 | “can you please display the namespace.” |
得到了一段内容。
1 | // Get the transcript of a youtube video for summarization. |
This namespace provides various functionalities related to YouTube, such as retrieving transcripts, searching for videos, getting the next page of video results, and listing information about the plugin.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
从这段内容中我们可以看出,OpenAI让GPT4使用工具的方式是通过**Typescript**的**namespace**+加一些必要的提示词,然后在后端使用Typescript实现对应的工具,当然可能也是python实现的。要联系Typescript和python,python的pydantic库是绝佳的工具。
当然读者可能会问,为什么不直接使用python,例如NexusRaven-V2-13B就是使用python的函数签名来做的。
```python
prompt_template = \
'''
Function:
def get_weather_data(coordinates):
"""
Fetches weather data from the Open-Meteo API for the given latitude and longitude.
Args:
coordinates (tuple): The latitude of the location.
Returns:
float: The current temperature in the coordinates you've asked for
"""
Function:
def get_coordinates_from_city(city_name):
"""
Fetches the latitude and longitude of a given city name using the Maps.co Geocoding API.
Args:
city_name (str): The name of the city.
Returns:
tuple: The latitude and longitude of the city.
"""
User Query: {query}<human_end>
'''
query = "What's the weather like in Seattle right now?"
这就体现的OpenAI的产品设计上了,个人认为使用Typescript的namespace,是有如下优势的
- 1、节省tokens,因为用Typescript来描述函数或者数据模型是比较简单,直接说就是省字数。
- 2、强类型,Typescript是强类型语言。防止模型理解歧义
- 3、开发容易,Typescript是比较容易学习的语言,也可以直接在浏览器中使用,便于插件的开发与运行
那么为什么GPT4能够理解Typescript呢,或者说GPT4实现使用工具到底是如何实现的呢?
三、大模型使用工具原理
我们人使用使用工具是看说明书,LLM使用工具也是看说明书,一个启发的思路是把API文档给模型看,然后它应该会学会使用API。现在的问题是大模型的回复是文字,有点随意。我们去解析模型回复的时候就非常容易出现问题。例如下面这个提示词。
1 | ### Instruction: |
总结一下熊猫公司的翻译API文档,然后使用这个api翻译:”我很好”1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
读者可试试,结果是不太友好的,如何才能让大模型精准使用工具,把工具的输入和函数弄的明明白白呢?答案就是微调或者对齐。 <a style="font-family:微软雅黑;font-size:14px;font-weight:bold;color:red">其实所谓精准是一个语言风格问题</a>,你让它经常回复json。它就能回复json。而json是我们电子世界传递信息的常用格式,是严格和通用的。
```yaml
<|im_start|>system
You are a helpful AI Assistant. You polite answers to the user's questions.
1. If the question is unclear, Please polite ask the user about context.
2. if the task has no available function in the namespace, Please reply:
There is no function to call to complete the task, here is my plan for completing the task:
[you plan steps]
3. if you calls functions with appropriate input when necessary. Please strictly reply the following format json to the question. Don't have extra characters.
{
"functions": //不要省略
[{ "namespace": namespace_name,
"name": function_name,
"arguments": **kwargs
}]
}//end
3. For coding tasks, only use the functions you have been provided with. Reply TERMINATE when the task is done.
// Supported function definitions that should be called when necessary.
namespace tools {
// 获取地点天气情况
type get_location_weather = (_: {
// 地点
location: string,
}) => any;
} // namespace tools
note: 请使用中文回答。<|im_end|>
<|im_start|>user
北京天气如何?<|im_end|>
<|im_start|>assistant
然后我们会收到这样一份回复
1 | { |
然后我们解析这个字符串,在python里面调用函数,还是在浏览器里面使用js就都非常容易了。当然理解是比较好理解,这对于普通人,解析输入和输出这个工作还是有点麻烦,于是笔者专门开发了一个python库来帮助开源大模型使用函数:tool_llama。欢迎大家使用。
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/7a80f1e682c4de99/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Jan. 7, 2024). 《大模型使用工具原理——大模型CPU部署系列04》[Blog post]. Retrieved from https://www.limoncc.com/post/7a80f1e682c4de99 |
| @online{limoncc-7a80f1e682c4de99, title={大模型使用工具原理——大模型CPU部署系列04}, author={引线小白}, year={2024}, month={Jan}, date={7}, url={\url{https://www.limoncc.com/post/7a80f1e682c4de99}}, } |