作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/5981c46065ab066d/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
一、internlm2的初步印象
说说个人观感,大模型在中国,有两股政府力量,一股是北京的智源、一股是上海人工智能实验室。在前期(202301-202401)智源的可谓风头十足,Aquila、BGE(BAAI General Embedding)、天宝1.0(智能线虫)。无论是学术还是产业引来一波关注。后来智源陷入了人事动荡。上海人工智能实验室自从发布internlm2后,开始的加大了宣传。OpenLLM开源社区也应该是得到了上海政府的支持,有一说一上海政府对大模型开源的支持应该比任何中国地方政府都要大。笔者认为要发展一方IT产业,政府支持关键基础设施开源应该是必由之路。而笔者所在的重庆目前似乎没有摸到门道,政府成立的一大帮国企做项目不是好方法。回到正题,书生.浦语建立了一整套开源体系,这包括:
- 数据:书生.万卷
- 预训练 :InternLM-Train
- 微调:XTuner
- 部署:LMDeploy
- 测评:OpenCompass
- 应用:AgentLego
非常全面了。对于算法应用工程师而言,我目前最关注的是后面的LMDeploy、OpenCompass、AgentLego。这里重点谈谈LMDeploy,相比于vllm、llama.cpp、fastllm、抑或是deepspeed MII。LMDeploy在部分模型的推理效率要高。这主要涉及TurboMind推理引擎int4支持的模型:Llama2、InternLM、InternLM2、QWen、QWen-VL、Baichuan、Baichuan2。其他模型最多只支持到int8,需要的资源比其他推理框架资源消耗多。所以大家还是要根据实际情况选择。
- 1、如果是ChatGLM粉丝就选fastllm
- 2、如果是书生.浦语粉丝就选LMDeploy
- 3、如果追求通用vllm、llama.cpp、deepspeed MII是不错选择,支持模型也最为广泛
二、internlm2一些关键要点
这里主要总结了笔者感兴趣的部分,不同人应该有不同的理解,大家轻拍。
2.1、数据如何去重
internlm2的技术报告是这样说的。互联网上存在大量重复文本,这可能会对模型训练产生负面影响。因此,我们采用了一种基于局部敏感哈希(LSH)的方法对数据进行模糊重复数据删除。更具体地说,我们使用了MinHash方法(Broder,1997),在5-gram的文档上建立了具有128个哈希函数的签名,并使用0.7作为重复数据删除的阈值。我们的目标是保留最新的数据,即对具有较大 CC 转储数量的数据进行优先级排序。我们获得了 LSH 重复数据删除后的重复数据[^1]。
而具体操作使用MinHash方法进行数据去重的步骤应该如下:
- 1、分词(Tokenization):
首先,将文档分割成小的单元,称为token,这些可以是单词、短语或其他定义好的文本单元。在上文中提到的操作中,使用了5-gram,即连续的5个tokens组成的序列。 - 2、构建MinHash签名:
对每个文档,执行以下步骤来构建其MinHash签名:- 生成一个随机的哈希函数集合,每个哈希函数都将tokens映射到一个整数上。
- 对于每个哈希函数,找到所有tokens的哈希值,并取最小值作为该哈希函数的代表。
- 重复上述步骤128次(或选择的其他次数),为每个文档生成128个这样的最小哈希值,形成一个MinHash签名。
- 3、计算Jaccard相似度:
对于每一对文档,通过比较它们的MinHash签名来计算Jaccard相似度。具体来说,统计两个签名中相同最小哈希值的数量,并除以签名的长度(在这个例子中是128),得到一个介于0和1之间的相似度分数。
设置阈值并过滤重复内容: - 4、设定一个阈值(如0.7),用于判断两个文档是否足够相似以至于被认为是重复的。如果两个文档的Jaccard相似度超过这个阈值,它们就被认为是潜在的重复内容。
去重决策:
根据相似度分数和设定的阈值,决定是否合并或删除重复的文档。通常,会选择保留质量最高的版本,并移除其他重复项。这个过程可以有效地在大规模数据集中识别和去除重复内容,同时保持计算效率。MinHash方法的优势在于它不需要对整个文档集合进行精确的相似度计算,而是通过MinHash签名来近似估计,这大大减少了计算资源的消耗。
来个最简单实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64from datasketch import MinHash, MinHashLSH
def word_ngrams(tokens, ngram_range=(1, 1), stop_words=None):
# 去除停用词
if stop_words is not None:
tokens = [w for w in tokens if w not in stop_words]
# handle token n-grams
min_n, max_n = ngram_range
if max_n != 1:
original_tokens = tokens
tokens = []
n_original_tokens = len(original_tokens)
for n in range(min_n, min(max_n + 1, n_original_tokens + 1)):
for i in range(n_original_tokens - n + 1):
tokens.append("".join(original_tokens[i: i + n]))
return tokens
# 创建一个 MinHash 对象
def create_minhash(sentence_data: str):
# list(sentence) 这里直接使用一个字作为一个token
data = word_ngrams(list(sentence_data), (1, 5))
_minhash = MinHash(num_perm=128) # num_perm 是哈希函数的数量,可以根据需要调整
for d in data:
_minhash.update(d.encode('utf8'))
return _minhash
# 创建一些示例数据(中文长句子)
sentences = [
"今天天气很好,阳光明媚,适合出门散步。",
"我喜欢读书,尤其是科幻小说。",
"这个城市的夜景非常漂亮,尤其是灯光璀璨的CBD区。",
"我的家乡是一个美丽的小镇,四季分明,景色宜人。",
"学习新知识让我感到充实和快乐。",
"我喜欢健身,每天都会去健身房锻炼。",
"这家餐厅的菜品非常美味,尤其是他们的特色菜。",
"我喜欢旅行,尤其喜欢去一些自然风光优美的地方。",
"听音乐是我放松心情的最爱之一。",
"听音乐是我心情放松的时候。",
"看电影是我周末最喜欢做的事情之一,我喜欢各种类型的电影。"
]
# 创建 MinHash 对象并插入到 LSH 中
# 也可以使用redis后端存储,对于大规模数据
lsh = MinHashLSH(threshold=0.5, num_perm=128) # threshold 是相似度阈值,可以根据需要调整
for idx, sentence in enumerate(sentences):
minhash = create_minhash(sentence)
lsh.insert(idx, minhash)
# 查找相似的集合
query_minhash = create_minhash('听音乐是我心情放松')
results = lsh.query(query_minhash)
# 输出相似度分数
for result in results:
minhash = create_minhash(sentences[result])
jaccard_similarity = query_minhash.jaccard(minhash)
print(f"与查询相似句子的索引是{result}, 相似度分数为: {jaccard_similarity}")
print(sentences[result])
# 与查询相似句子的索引是9, 相似度分数为: 0.59375
# 听音乐是我心情放松的时候。
2.2、如何提升数据质量
使用了综合的安全策略,结合了“域屏蔽”、“单词屏蔽”、“色情分类器”和“毒性分类器”来过滤数据。具体来说,我们构建了一个包含大约 13M 个不安全域的块域列表和一个包含 36,289 个不安全词的块词列表,用于初步数据过滤。鉴于单词阻塞可能会无意中排除大量数据,我们在编制阻塞词列表时选择了谨慎的方法。这些分类器都是微调BERT模型。
由于各种分类器比较多,internlm2技术报告总结选择过滤阀值的经验[^1]:
为每个领域定制阈值,而不是寻求通用解决方案。例如,连词的统计筛选器不适用于长代码数据,该数据通常没有任何连词。同样,教科书、研究论文、小说和专利都表现出独特的特征。通用阈值可能会对大量数据进行错误分类。同样的逻辑也适用于跨不同语言设置阈值;因此,我们分别调整每个域的阈值。
使用验证集来简化流程,仅关注边缘案例。与基于学习的特征提取器或评分器不同,我们的统计和困惑过滤器在同一领域内产生平滑的结果。它使我们能够专注于位于阈值附近的样本,从而简化了阈值的调整,因为我们只需要确定是降低还是提高阈值。Lv et al. ( 2024) 说明了数据集群以及来自特定过滤器的分数,展示了我们提出的过滤器的可解释性。
2.3、如何实现200k长度
技术报告中说了训练的问题:
InternLM2 的训练过程从 4K 上下文语料库开始,随后过渡到具有 32K 上下文的语料库。50%的数据仍然短于4096个令牌,而不是只使用32k语料库。这个长上下文训练阶段约占总步骤的 9%。当适应这些较长的序列时,我们将旋转位置嵌入 (RoPE) 基数从 50,000 调整到 1,000,000,确保对长上下文进行更有效的位置编码。
这里补充一下代码中的DynamicNTKScalingRotaryEmbedding是怎么回事?先看模型里面的配置文件
1 | { |
总的来说,DynamicNTK的核心思想是推理长度小于等于训练长度时,不进行插值;推理长度大于训练长度时,放大base动态插值。具体来说当我们要计算某个token的嵌入向量的第 $i$ 组的旋转位置编码的时候,我们需要计算 $m\theta_i=m*\text{base}^{-\frac{2i}{d}}$ 。为了使得这个原理变的显然,笔者稍微改变一下符号。
$$\begin{align}
\rho(\text{position},\text{dim_index})=\cos\big(\text{position}\times\text{base}^{-\frac{2\times \text{dim_index}}{\text{dim}}}\big)-\mathrm{i}\times\sin\big(\text{position}\times\text{base}^{-\frac{2\times \text{dim_index}}{\text{dim}}}\big)
\end{align}$$
我们知道旋转位置编码有一个特点就是如果我们固定维度的索引 $\text{dim_index}$, 单独观察位置编码和token位置的关系。
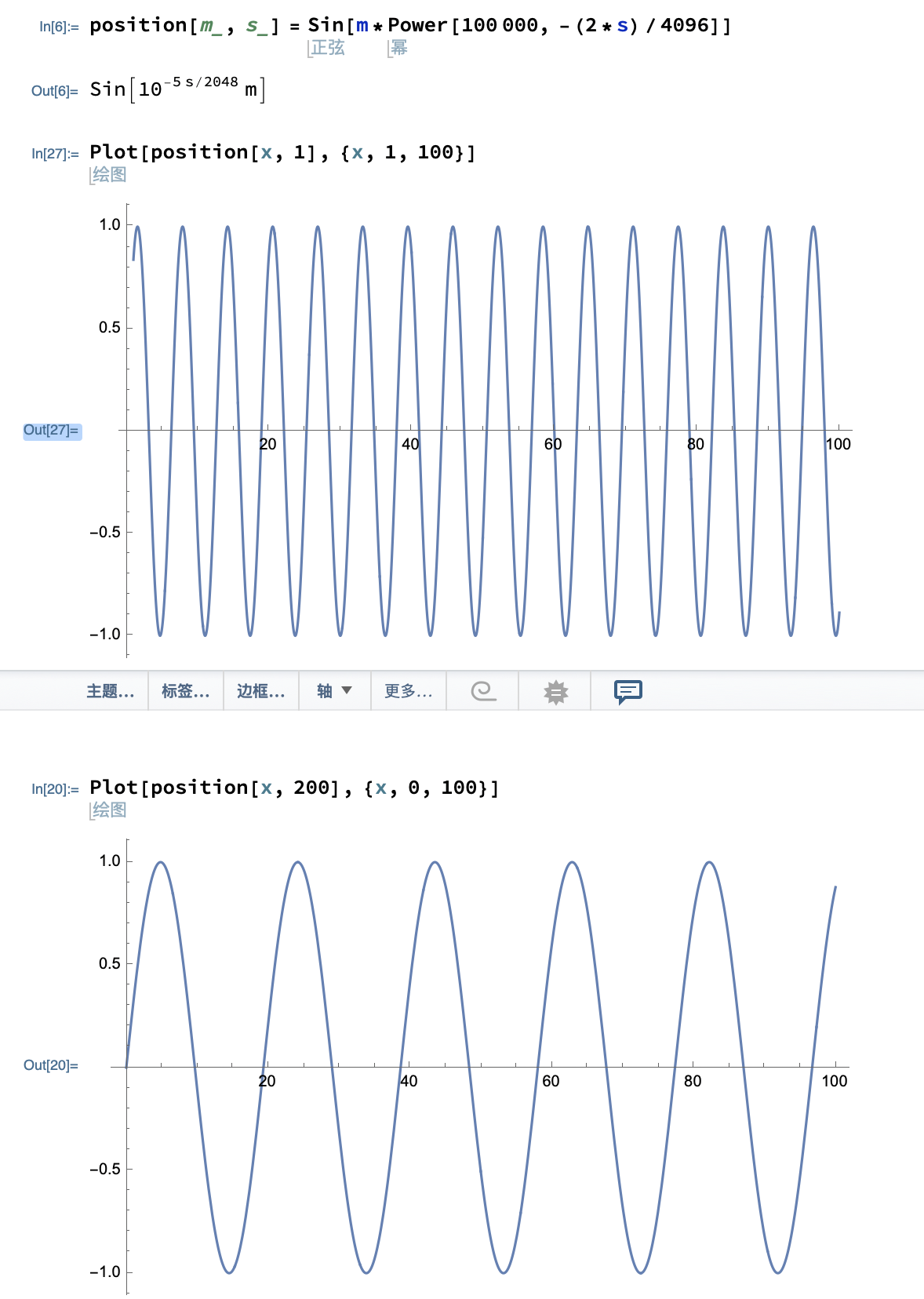
对于嵌入向量的第一组编码,观察如果该嵌入向量对应token在第1位到100位的位置编码 $sin$ 值。这个值震荡的很厉害,或者说在嵌入向量低维度位置编码是高频信息。在观察嵌入向量的第200组编码,震荡明显减少,或者说在嵌入向量高维度位置编码是低频信息。也可以这么说:
1、token嵌入向量的低维度数据与token位置是经历过充分训练的。说的更加明白点如果 $\mathrm{Vector}(\text{token}={\small 我}])[0:1]=[a,b]$ ,则编码是这样的:
$$\begin{align}
a\times \cos(m\text{base}^{-\frac{1}{4906/2}})-b\times\sin(m\text{base}^{-\frac{1}{4906/2}})
\end{align}$$
也就是 $a,b$ 是经历过 $m$ 这个世面的。或者可以这样理解:一个圆上大部点都见过这个token嵌入向量的低维度数据
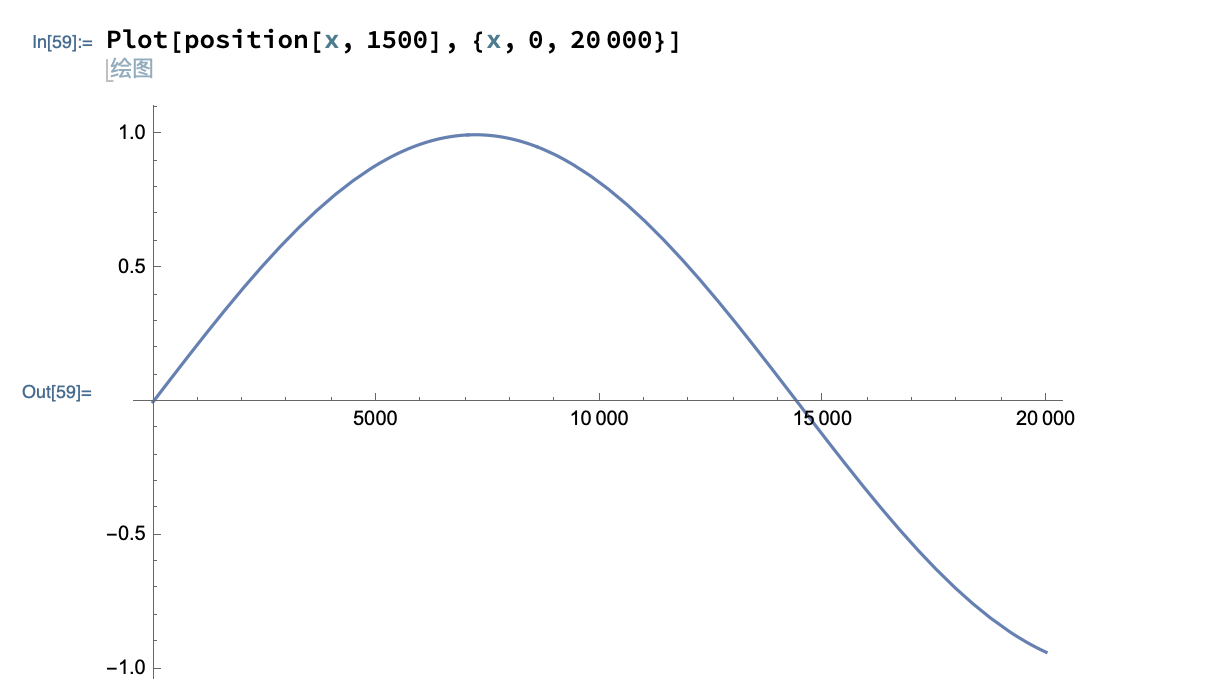
2、token嵌入向量的高维度数据,例如下图的第1500组数据,即使有20k上下文,高维度数据也没有见过圆上的所有点。
我们来看看InternLM2对DynamicNTK的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class InternLM2DynamicNTKScalingRotaryEmbedding(InternLM2RotaryEmbedding):
"""InternLM2RotaryEmbedding extended with Dynamic NTK scaling.
Credits to the Reddit users /u/bloc97 and /u/emozilla.
"""
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
if seq_len > self.max_position_embeddings:
base = self.base * (
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
) ** (self.dim / (self.dim - 2))
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
其实最关键就这行
1 | if seq_len > self.max_position_embeddings: |
也就是说
$$\begin{align}
m\theta_i=m\times\bigg(\text{base}\times[\delta*\frac{l}{L}-(\delta-1)]^{\frac{d}{d-2}}\bigg)^{-\frac{2i}{d}}
\end{align}$$
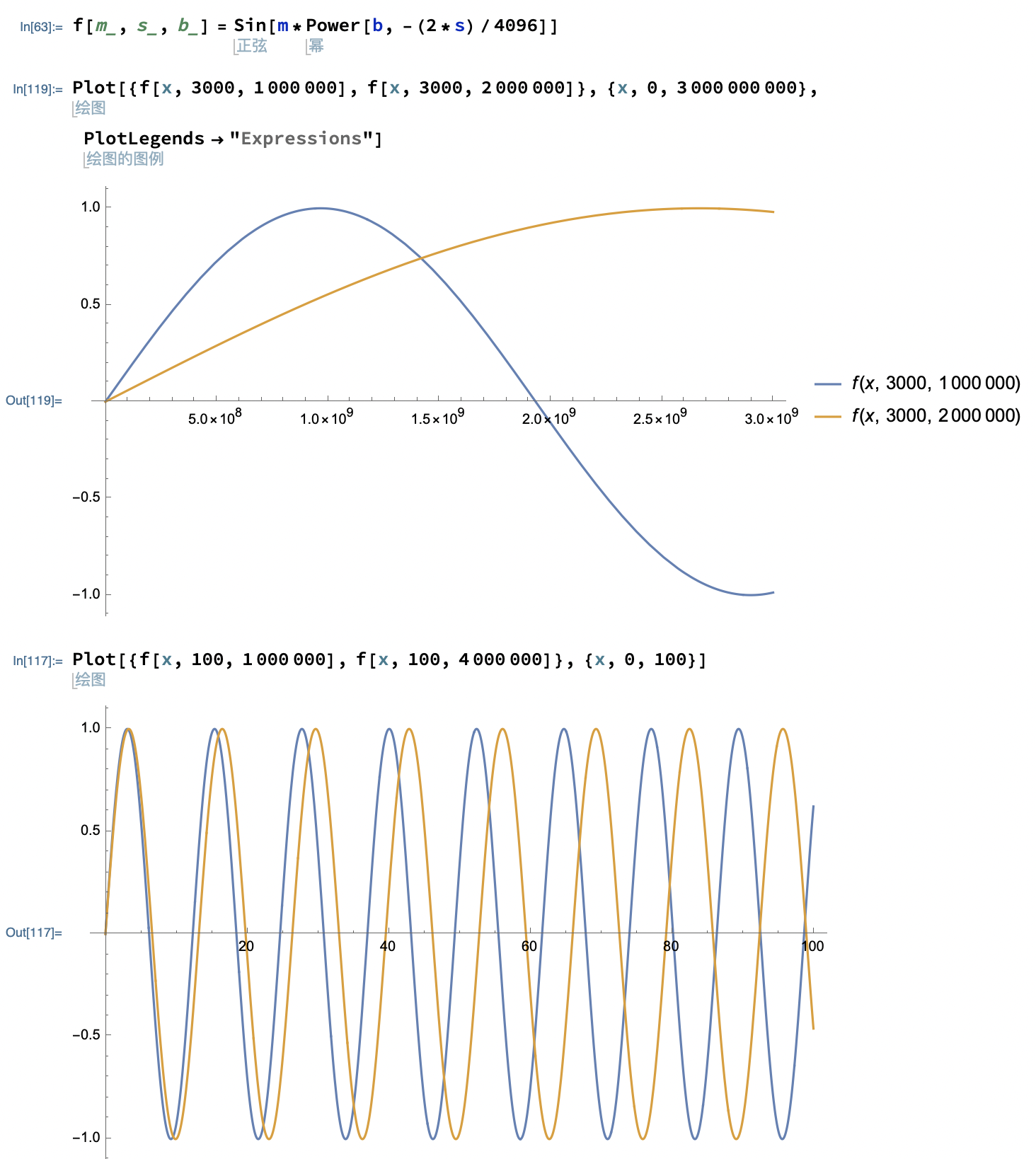
让我们来举个例子base = 1000000、经过训练的最大位置编码是4096。当我们计算6000这个位置,也就是第3000组的时候,我们扩大base=2000000。这相当于拉伸曲线,即用圆上训练过的点来表示,这样就实现了外推。
2.4、InternLM2的损失函数设计
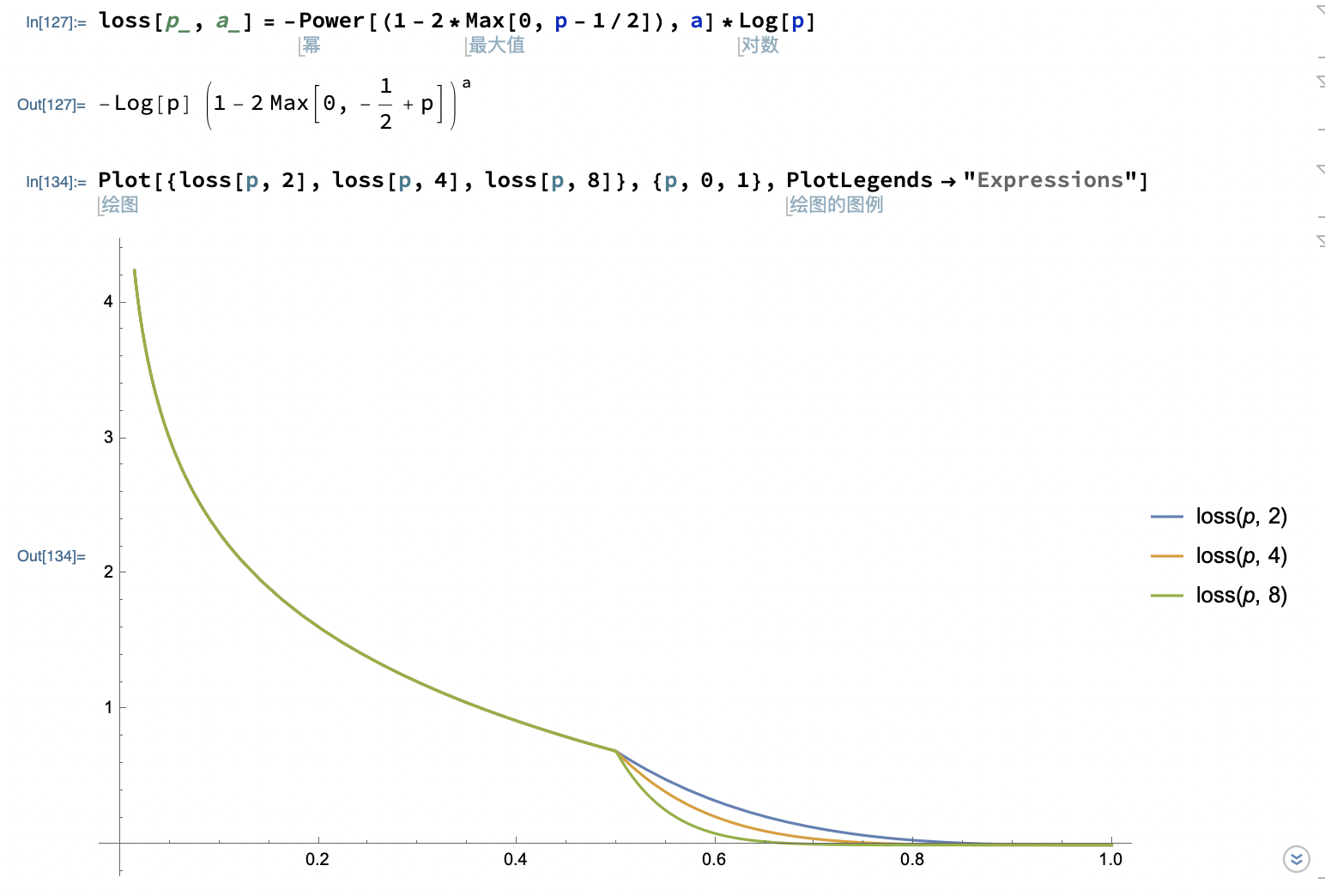
InternLM2使用的是有条件 PPO 的训练,根据技术报告的说法,InternLM2使用的是所谓条件奖励模型其实就是加了提示词,对各个领域的偏好单独打分。而不是一视同仁。这么看确实更加科学。损失函数使用了Focal Loss[^2]
$$\begin{align}
L_{ranking} = -\bigg(1-2\times \max[0,P_{i,j}-\frac{1}{2}]\bigg)^{\gamma}\log[P_{i,j}]
\end{align}$$
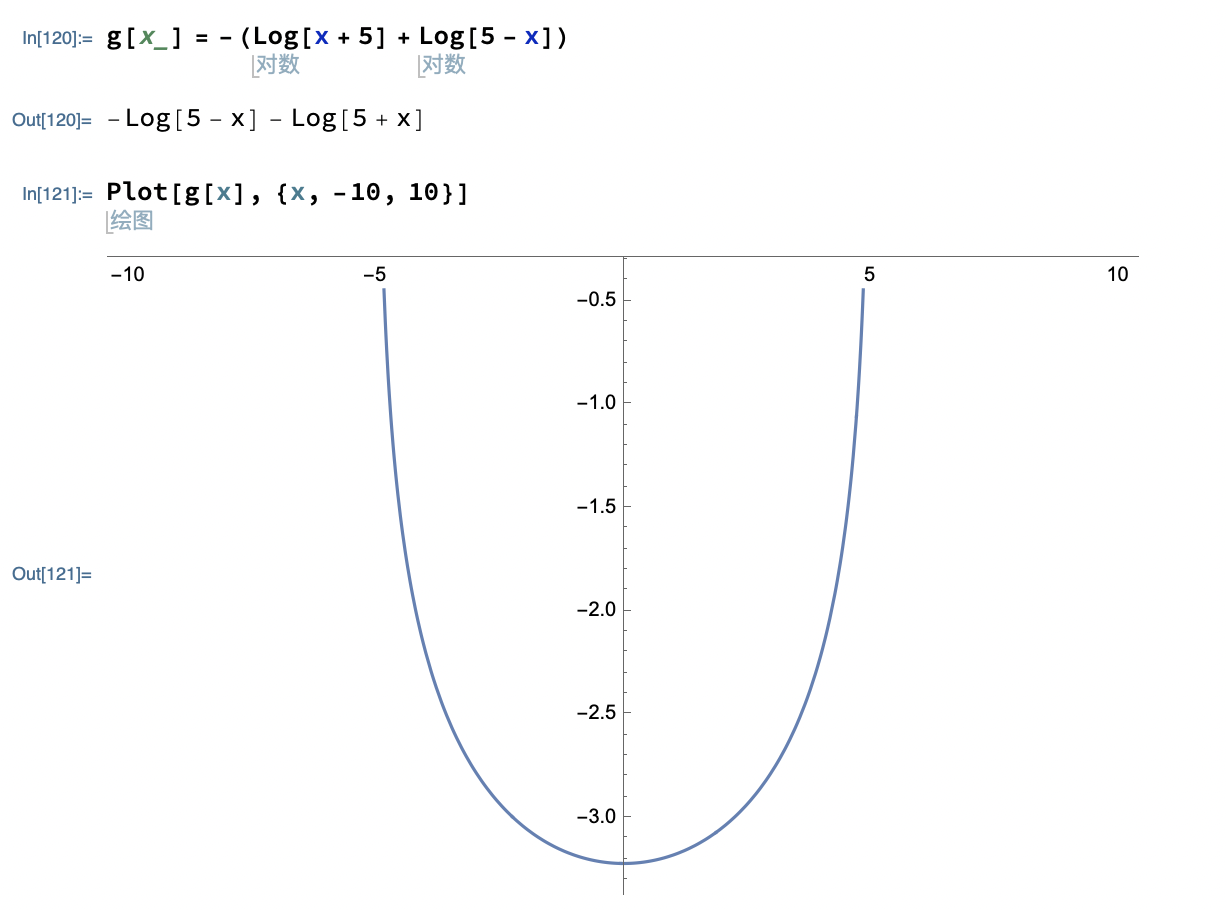
$$\begin{align}
L_{penalty}=-\big(\log[5+x]+\log[5-x]\big)
\end{align}$$
三、一个简单的评述
1、InternLM2-20b的性能还是比较全面的,技术报告也有很多细节,先写这么多吧,毕竟internStudio给我了很多免费算力哇。改天在做分享。
2、要说InternLM2亮眼之处:1、PPO的条件奖励模型,2、对工具的支持、3、200k上下文,不过你要使用LMDeploy,llama.cpp只支持原生的32k。4、整体性能提升了
四、参考文献
[^1]: Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., et al. (2024, March 25). InternLM2 Technical Report. arXiv. http://arxiv.org/abs/2403.17297. Accessed 29 March 2024
[^2]: Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2018, February 7). Focal Loss for Dense Object Detection. arXiv. http://arxiv.org/abs/1708.02002. Accessed 29 March 2024
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/5981c46065ab066d/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Mar. 27, 2024). 《01解读技术报告初识书生.浦语2——internlm2系列》[Blog post]. Retrieved from https://www.limoncc.com/post/5981c46065ab066d |
| @online{limoncc-5981c46065ab066d, title={01解读技术报告初识书生.浦语2——internlm2系列}, author={引线小白}, year={2024}, month={Mar}, date={27}, url={\url{https://www.limoncc.com/post/5981c46065ab066d}}, } |