作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/1a40fb91b4777636/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
英国作家塞缪尔·约翰逊说过
记忆的真正艺术是注意力艺术!(The true art of memory is the art of attention!)

一、引言
什么是记忆? 当前[2025]要让模型拥有记忆,大家倾向于构建复杂的上下文工程(Context Engineering),这种记忆是外置非内生的,而人类的记忆并不是这样的。这个工程化的记忆机制注定只是当前技术下的短期解决方法。注意力机制的QKV体现了数据库的查询检索存储框架。线性化后的注意力机制也同样体现了这一点。随着Delta学习规则的引入, 将状态(记忆)更新由加法规则改为了Delta学习规则, 诞生了DeltaNet[^1],从而启发了人们进一步思考什么是记忆。Delta学习规则涉及的对角加秩一矩阵(一种广义Householder变换)是一种很重要的形式,出现了很多类似RWKV7[^2]的改进方案,如Gated DeltaNet[^3]、TTT[^4]、谷歌Titans[^5]也在这个方向上进行探索,最近2025WAIC上的岩芯数智(RockAI)也展示了一种可微的神经网络记忆单元[^6]也令人印象深刻。在大模型时代关于什么是记忆、记忆是如何工作这个问题似乎已经走的足够远了,其中Miras[^7]总结了这些线性RNN的特点,并提出了一个统一框架。本文将围绕记忆这个主题总结最近以来(2025年)的一些进展和个人的看法。
限于文章长度,本文对很多内容未做深度讨论,主要展示现代RNN状态更新如何解决记忆这个问题,同时描述这种更新的内在统一框架。
二、原始线性注意力
2.1、线性注意力的并行计算
将注意力机制变为线性注意力最简单的方法就是去掉softmax:
$$\begin{align}
\mathrm{Attention}(\bm{Q}, \bm{K}, \bm{V})=\mathrm{softmax}\left[\frac{\bm{Q} \bm{K}^T}{\sqrt{d_k}}\odot \bm{M}\right] \bm{V}
\end{align}$$
这样就得到了最简单的线性注意力机制:
$$\begin{align}
\mathrm {LinearAttention}(\bm{Q}, \bm{K}, \bm{V})
=\left(\bm{Q}\bm{K}^\T\odot \bm{M}\right) \bm{V}
\end{align}$$
其中:
$\bm{Q} \in \mathbb{R}^{n \times d_q}$:查询矩阵
$\bm{K} \in \mathbb{R}^{n \times d_k}$:键矩阵
$\bm{V} \in \mathbb{R}^{n \times d_v}$:值矩阵
$d_q=d_k=d_v$
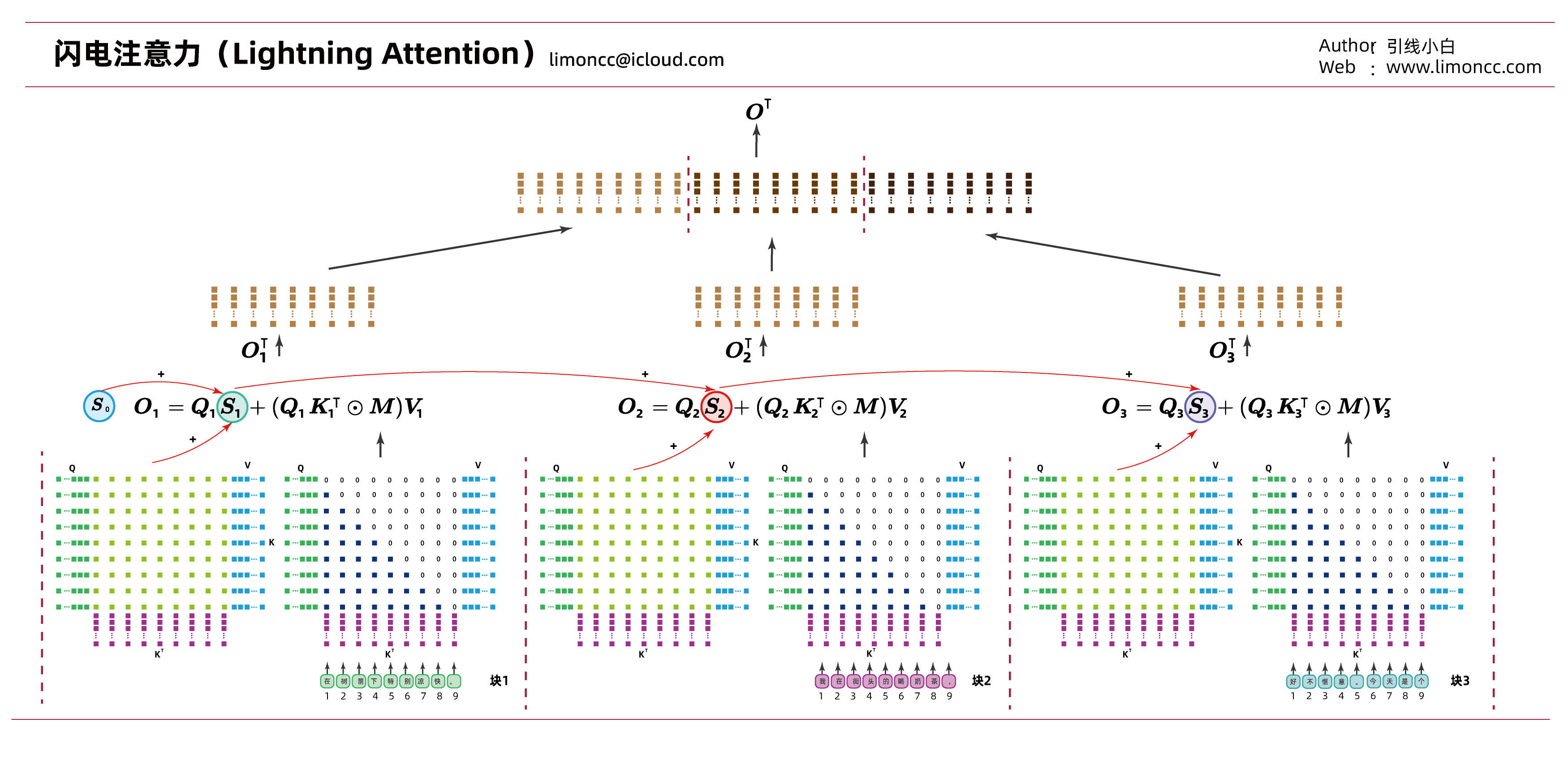
在线性注意力中外积 $\bm{K}^\T \bm{V}$和累积求和是可交换的。也就是说可以定义一个状态 $\bm{S}_t$, 通过顺序计算 $\bm{S}_t = \bm{S}_{t-1} + \bm{k}_t\bm{v}_t^\T$ 来求矩阵 $\bm{K}^\T \bm{V}$,利用这个特性可以得到minimax的闪电注意力(Lightning Attention)[^8]:块内并行, 块间依赖。这样在小块内并行计算可以利用HBM实现高性能计算,下面以3块分割举例,在序列方向上将token分为三部分,这样有
$$\begin{align}
\begin{bmatrix}
\bm{O}_1\\
\bm{O}_2\\
\bm{O}_3\\
\end{bmatrix}=
\begin{bmatrix}
\bm{Q}_1\\
\bm{Q}_2\\
\bm{Q}_3\\
\end{bmatrix}
\begin{bmatrix}
\bm{S}_0\\
\bm{S}_1\\
\bm{S}_2\\
\end{bmatrix}+
\left(
\begin{bmatrix}
\bm{Q}_1\\
\bm{Q}_2\\
\bm{Q}_3\\
\end{bmatrix}
\begin{bmatrix}
\bm{K}_1 & \bm{K}_2 & \bm{K}_3
\end{bmatrix}\odot
\begin{bmatrix}
\bm{E} & \bm{0} &\bm{0} \\
\bm{0} & \bm{E} &\bm{0} \\
\bm{0} & \bm{0} &\bm{E} \\
\end{bmatrix}
\begin{bmatrix}
\bm{V}_1\\
\bm{V}_2\\
\bm{V}_3\\
\end{bmatrix}
\right)
\end{align}$$
其中 $\bm{S}_0=\bm{0}$, 使用$\bm{K}^\T \bm{V}$外积的求和模式有:
$$\begin{align}
\begin{bmatrix}
\bm{O}_1\\
\bm{O}_2\\
\bm{O}_3\\
\end{bmatrix}=
\begin{bmatrix}
\bm{Q}_1\\
\bm{Q}_2\\
\bm{Q}_3\\
\end{bmatrix}
\begin{bmatrix}
\bm{0}\\
\bm{S}_0+ \bm{K}_1^\T\bm{V}_1\\
\bm{S}_1+ \bm{K}_2^\T\bm{V}_2\\
\end{bmatrix}+
\left(
\begin{bmatrix}
\bm{Q}_1\\
\bm{Q}_2\\
\bm{Q}_3\\
\end{bmatrix}
\begin{bmatrix}
\bm{K}_1 & \bm{K}_2 & \bm{K}_3
\end{bmatrix}
\odot
\begin{bmatrix}
\bm{E} & \bm{0} &\bm{0} \\
\bm{0} & \bm{E} &\bm{0} \\
\bm{0} & \bm{0} &\bm{E} \\
\end{bmatrix}
\begin{bmatrix}
\bm{V}_1\\
\bm{V}_2\\
\bm{V}_3\\
\end{bmatrix}
\right)
\end{align}$$
展开其实就有
$$\begin{align}
\bm{O}_\tau
&= \bm{Q}_\tau \bm{S}_{\tau}+\left(\bm{Q}_\tau\bm{K}_\tau^\T\odot \bm{M}\right) \bm{V}_\tau\\
\bm{S}_{\tau}
&=\bm{S}_{\tau-1}+ \bm{K}_\tau^\T \bm{V}_\tau
=\bm{S}_{\tau-1}+\sum_{i=1}^n\bm{k}_i \bm{v}_i^\T
\end{align}$$
其中 $n=\text{size}(block)$, $\dim[\bm{S}]=d_k\times d_v$,即块内token的数量。这就是最原始的线性注意力和其并行计算。
那么这些线性注意力机制到底应该如何理解,下面先回顾一下历史。
2.2、Hebb学习规则
1949年,心理学家 Hebb 最早提出了关于神经网络学习机理的“突触修正”的假设。该假设指出,当神经元的突触前膜电位与后膜电位同时为正时,突触传导增强,当前膜电位与后膜电位正负相反时,突触传导减弱。也就是说”神经元共同激活则连接增强”(”cells that fire together, wire together”)。用数学公式就是
$$\begin{align}
\Delta w= x_iy_i
\end{align}$$
神经网络是通过其权重和连接结构来表达信息的记忆,大多数现有架构将记忆视为由输入引起的神经更新过程,并将学习定义为在给定目标的情况下获取有效且有用记忆的过程。通过这一视角:
对于Transformer的注意力机制而言
- 1、将键和值附加到上下文(KV Cache)中来更新记忆,这里没有压缩。
- 2、然后通过查找查询向量 $\bm{q}$与键向量 $\bm{k}$之间的相似性来检索查询向量对应的记忆 $\bm{v}$,然后利用
该相似性对值向量进行加权以生成输出
Transformer的注意力机制最大的问题是长下文的大显存需求和有限显存的矛盾,而线性注意力没有这个问题,它的状态需要的显存是恒定的。原始的线性注意力其实是Hebb学习规则的结果,它将历史数据压缩为固定大小的矩阵型记忆,并把上下文信息不断地压缩到状态 $\bm{S}$中。
$$\begin{align}
\underbrace{\bm{S}_\tau}_{当前累积记忆}=\underbrace{\bm{S}_{\tau-1}}_{历史累积记忆}+\underbrace{\bm{k}_\tau \bm{v}_\tau^\T}_{当前记忆}
\end{align}$$
由于状态 $\bm{S}$的大小有限,其能容纳的记忆和上下文也是有限的。简单的说它会爆,这就说明这种加性更新表达能力是有限,这样就有了后面的$\delta$ 规则。
三、绕不开的DeltaNet
3.1、历史悠久的 $\delta$ 规则
$\delta$ 规则顾名思义就是学习输出与目标值的差值来学习,它很容易由输出值与期望值的最小平方误差条件推导出来
$$\begin{align}
\min_{\bm{S}} \ell(\bm{S})=\frac{1}{2}|\bm{S}\bm{k}-\bm{v}|_F^2
\end{align}$$
这里要注意 $\bm{S}$的维度和上面线性注意力状态的维度不一样 $\dim[\bm{S}]=d_v\times d_k$, 之所以要转置一下,是为了接下叙述的方便, 符号也会节省很多。回顾公式,实际上是在说:将信息 $\bm{v}$ 存入记忆其实就是让 $\bm{k}$ 能在记忆 $\bm{S}$ 中尽可能地回忆起 $\bm{v}$,且让它们的差值越小越好。实际上有
$$\begin{align}
\mathrm{d}\ell
&=\frac{1}{2}\mathrm{d}\mathrm{tr}\big[[\bm{S}\bm{k}-\bm{v}]^\T[\bm{S}\bm{k}-\bm{v}]\big]\\
&=\frac{1}{2}\mathrm{d}\mathrm{tr}\big[\bm{k}^\T\bm{S}^\T \bm{S}\bm{k}-\bm{k}^\T\bm{S}^\T \bm{v}- \bm{v}^\T \bm{S}\bm{k}+\bm{v}^\T \bm{v}\big]\\
&=\frac{1}{2}\big(
\mathrm{d}\mathrm{tr}[\bm{k}^\T\bm{S}^\T \bm{S}\bm{k}]
-\mathrm{d}\mathrm{tr}[\bm{k}^\T\bm{S}^\T \bm{v}]
-\mathrm{d}\mathrm{tr}[ \bm{v}^\T \bm{S}\bm{k}]
\big)\\
&=\frac{1}{2}\big(
\mathrm{tr}[\bm{k}^\T\mathrm{d}\bm{S}^\T \bm{S}\bm{k}]
+\mathrm{tr}[\bm{k}^\T\bm{S}^\T \mathrm{d}\bm{S}\bm{k}]
-2\mathrm{d}\mathrm{tr}[\bm{v}^\T\bm{S}\bm{k}]
\big)\\
&=\frac{1}{2}\big(
2\mathrm{tr}[\bm{k}^\T\bm{S}^\T \mathrm{d}\bm{S}\bm{k}]
-2\mathrm{d}\mathrm{tr}[\bm{v}^\T\bm{S}\bm{k}]
\big)\\
&=\mathrm{tr}[\bm{k}^\T\bm{S}^\T \mathrm{d}\bm{S}\bm{k}]
-\mathrm{tr}[\bm{v}^\T\mathrm{d}\bm{S}\bm{k}]\\
&=\mathrm{tr}[\bm{k}\bm{k}^\T\bm{S}^\T \mathrm{d}\bm{S}]
-\mathrm{tr}[\bm{k}\bm{v}^\T\mathrm{d}\bm{S}]\\
&=\mathrm{tr}\bigg[\big[\bm{S}\bm{k}\bm{k}^\T-\bm{v}\bm{k}^\T\big]^\T\mathrm{d}\bm{S}\bigg]
\end{align}$$
于是有
$$\begin{align}
\nabla_{\bm{S}}\ell = \bm{S}\bm{k}\bm{k}^\T-\bm{v}\bm{k}^\T
\end{align}$$
做梯度更新有
$$\begin{align}
\bm{S}:=\bm{S}-\beta(\bm{S}\bm{k}\bm{k}^\T-\bm{v}\bm{k}^\T)
=\bm{S}\big[\bm{E}-\beta\bm{k}\bm{k}^\T\big]+\beta\bm{v}\bm{k}^\T
\end{align}$$
加上下角标就有
$$\begin{align}
\bm{S}_{t}=\bm{S}_{t-1}\big[\bm{E}-\beta_t\bm{k}_t\bm{k}_t^\T\big]+\beta_t\bm{v}_t\bm{k}_t^\T
\end{align}$$
这样就得到了DeltaNet的状态更新公式。注意到状态更新公式是在推理中计算的。于是基于上述推导,实际上就实现了在推理中进行梯度下降学习,也就是说一定程度上实现了边推理边学习的元学习状态。万里长征总是算迈出了第一步。
现在回顾一下这种做法的历史,2021年的一篇论文《Linear Transformers Are Secretly Fast Weight Programmers》说的是线性Transformer 实际上是快权重编程。而快权重编程FWP(Fast Weight Programmers)的概念实际上是上世纪90年代的思想(Schmidhuber, 1991; 1992; 1993; AI Blog, 2021)。这里引用论文的原文来介绍一下快权重编程:
在标准神经网络中,权重在训练后保持固定,不同于激活值,后者在测试时会根据输入发生变化。快速权重的基本思想是使权重也变得可变且输入相关。这一概念被称为突触调制(vonder Malsburg, 1981),一种用于神经网络中可变绑定的方法(例如,Greff等人(2020)的最新综述),或动态连接(Feldman, 1982)。Von der Malsburg将有效权重定义为传统、上下文无关的慢权重与快速变化、上下文相关的快权重的(乘法)叠加。Hinton & Plaut(1987)研究了一个网络,在模型再训练场景中,该网络通过(加法)叠加两种不同学习率的两组权重。然而,在 1991 年之前,没有任何网络通过梯度下降学习来快速计算另一网络或自身快权重存储的变化。
一个传统的慢网络通过慢权重持续改变或重新编程快网络的快权重,使快权重实际上依赖于给定输入流的时空上下文。简而言之,慢网络学习如何编程其快网络。
回顾公式
$$\begin{align}
\bm{S}_{t}=\underbrace{\bm{S}_{t-1}\big[\bm{E}-\beta_t\bm{k}_t\bm{k}_t^\T\big]}_{历史记忆衰减}+\underbrace{\beta_t\bm{v}_t\bm{k}_t^\T}_{新增记忆}
\end{align}$$
不仅有加性记忆,也引入了记忆遗忘(删除)的机制,从而实现了在固定记忆大小下更好的表达能力。
3.1、对角加秩一矩阵(DPLR)
这里要进一步探究DeltaNet中的状态衰减因子 $\bm{E}-\beta_t\bm{k}_t\bm{k}_t^\T$,它实际上和矩阵计算中重要的Householder变换极为相似,除了 $\beta_t$的不一样。实际上它几何意义和Householder变换是差不多的。在开始解释前,注意到该矩阵其实是一个对角矩阵+秩一矩阵,这样矩阵有些特殊的性质。
$$\begin{align}
\bm{H} =\underbrace{\bm{E} \vphantom{\beta\bm{k}\bm{k}^\T}}_{对角矩阵} -\underbrace{\beta\bm{k}\bm{k}^\T}_{秩一矩阵\,\mathrm{rank}[\bm{k}\bm{k}^\T]=1}
\end{align}$$
首先明确一下矩阵和向量维度: $\dim[\bm{S}]=d_v \times d_k$, 实际有 $\bm{S}^\T=[\bm{s}_1,\cdots,\bm{s}_{d_v}]$, $\dim[\bm{s}]=\dim[\bm{k}]=d_k$,所以有
$$\begin{align}
\bm{s}_{t}^\T= \bm{s}_{t-1}^\T[\bm{E}-\beta_t\bm{k}_t\bm{k}_t^\T]\Leftrightarrow
\bm{s}_{t}=[\bm{E}-\beta_t\bm{k}_t\bm{k}_t^\T]\bm{s}_{t-1}
\end{align}$$
实际上会对键矩阵做归一化再求状态,这样就有 $|\bm{k}|=1$, 那么$\bm{s}_{t-1}$在 $\bm{k}_t$上的投影是
$$\begin{align}
\mathrm{proj}_{\bm{k}_t}(\bm{s}_{t-1})= \bm{k}_t ^\T\bm{s}_{t-1}\bm{k}_{t}=
\bm{k}_{t}\bm{k}_t ^\T\bm{s}_{t-1}
\end{align}$$
这样就有
$$\begin{align}
\bm{s}_{t}=\bm{s}_{t-1}-\beta_t\mathrm{proj}_{\bm{k}_t}(\bm{s}_{t-1})
\end{align}$$
那么对角加秩一矩阵的实质是通过迭代变换构建记忆状态: 对于任意向量 $\bm{s}$,变换后沿 $\bm{k}$方向的分量被衰减、保留或放大,而正交分量保持不变,从而实现精细化的记忆控制。 $\beta$用于动态调整记忆衰减强度,确保模型仅遗忘与当前任务无关的信息。一张图说明问题:

一个简单例子:假设状态空间为 $\mathbb{R}^2$,输入键向量$\mathbf{k}_t = [1, 0]^\T$,状态 $\bm{S}_{t-1} = [3, 2]^\T$,取 $\beta_t = 0.5$.
$$\begin{align}
\bm{H}_t = \bm{E} - 0.5 \begin{bmatrix} 1 \ 0 \end{bmatrix} \begin{bmatrix} 1 & 0 \end{bmatrix} = \begin{bmatrix} 0.5 & 0 \ 0 & 1 \end{bmatrix}
\end{align}$$
$$\begin{align}
\bm{S}_t = \bm{H}_t\bm{S}_{t-1} = \begin{bmatrix} 0.5 & 0 \ 0 & 1 \end{bmatrix} \begin{bmatrix} 3 \ 2 \end{bmatrix} = \begin{bmatrix} 1.5 \ 2 \end{bmatrix}
\end{align}$$
几何效果:
- 平行分量:沿 $x$-轴的分量从 3 衰减至 1.5(衰减率 50%)。
- 正交分量:沿 $y$-轴的分量保持 2 不变。
- 物理意义:模型遗忘 $x$-方向的历史信息,保留 $y$-方向的记忆。
对于输入序列:[The, quick, brown, fox],变换的效果:
- 键向量 $\bm{k}(quick)$衰减无关修饰词(如$\bm{k}(The)$),保留核心动词信息。
- 键向量 $\bm{k}(fox)$衰减动物无关特征,强化主语一致性。
3.3、RWKV7的状态更新
这里不打算深入RWKV7的细节,只讨论状态(记忆)更新公式。
$$\begin{align}
\bm{S}_t= \bm{S}_{t-1}\big[\underbrace{\mathrm{diag}[\bm{w}_t]}_{累积记忆衰减}-\underbrace{\bm{\kappa}_t(\bm{\beta}_t\odot\bm{\kappa}_t)^\T}_{历史记忆遗忘}\big]+ \underbrace{\bm{v}_t(\bm{\eta}_t\odot\bm{k}_t)^\T}_{新增记忆增强}
\end{align}$$
1、$\bm{\kappa}_t=\bm{k}_t\odot \bm{\xi}$,这里笔者认为是一种过参数化,增加表达力。这里的类似键矩阵 $\bm{k}$的矩阵已经和注意力机制中的 $\bm{k}$所起的作用大不相同,具体笔者将在接下来的博文中详细解释。
2、引入了累积记忆的衰减参数$\mathrm{diag}[\bm{w}_t]$
3、将学习率精细化,给遗忘记忆和新增记忆不同的学习率
4、学习率向量化,精确到每个特征维度(通道维度)
总的来说RWKV7的状态更新,做很多细节化的处理,对比最原始的线性注意力的加性状态已经是不可同日而语, 对比DeltaNet的状态更新也是做了更加精细处理,进一步增强了表达能力。
四、Titans的解释
对原始线性注意力、DeltaNet的更新规则、RWKV7的更新规则有了解后,有一个自然的问题就提出来了:这个记忆更新规则背后的统一框架是什么? google的Titans给出了一个顺理成章的解释:记忆依赖惊奇更新。
4.1、定义惊奇度
现代线性模型记忆视角将学习定义为获取有效且有用记忆的过程。在此基础上,可以将循环神经网络(RNN)的隐藏状态视为记忆单元,模型旨在将信息压缩到其中。相应地,在一般的循环神经网络形式中,隐藏状态可以被视为记忆单元,而递归过程可以分解为记忆单元中的读取和写入操作。令 $\mathcal{M}$为记忆, $\bm{X}_{n\times d}$作为输入,其中 $\bm{x}_t$是时刻 $t$的输入, $\bm{y}_t$是时刻 $t$的输出。那么有
$$\begin{align}
\mathcal{M}_t &= \mathrm{write}(\mathcal{M}_{t-1},\bm{x}_t)\\
\bm{y}_t &= \mathrm{read}(\mathcal{M}_t,\bm{x}_t)
\end{align}$$
那么如何构造这样记忆模块。简单的想法是训练一个神经网络并期望它能够记忆其训练数据。然而,记忆在神经网络中几乎一直被认为是一种不期望的现象:
- 1、它会限制模型的泛化能力
- 2、引发隐私问题
- 3、训练数据的记忆在测试时可能并不有益,因为在测试时数据可能是分布外的
这样最好是有一个在线元模型,该模型学习如何在测试时记忆或遗忘数据。在这种设置下,模型学习一个能够进行记忆的函数,但它并未过拟合训练数据,从而在测试时实现更好的泛化能力。这样训练记忆的关键思想就是将其训练视为一个在线学习问题,目标是将过去的信息 $\bm{x}_1\cdots \bm{x}_{t-1}$压缩到长期神经记忆模块 $\mathcal{M}_t$的参数中。违反预期的事件(即具有惊奇性)对人类来说更具记忆性。受此启发,可以为模型定义一个简单的惊讶度指标:
$$\begin{align}
\nabla\ell(\mathcal{M}_{t-1},\bm{x}_t)
\end{align}$$
即其相对于输入的梯度。梯度越大,表示输入数据与过去数据的差异越大。因此,利用这个惊讶度指标,可以更新记忆如下:
$$\begin{align}
\mathcal{M}_t = \mathcal{M}_{t-1} - \theta_t\nabla\ell(\mathcal{M}_{t-1},\bm{x}_t)
\end{align}$$
4.2、惊奇分解
这种惊奇度指标(surprise metric)可能会导致错过一些重要的信息,这些信息出现在一个重大惊喜事件之后。也就是说,在经过几次惊奇步骤后,梯度可能会变得非常小,从而使模型陷入平坦区域(即局部极小值),并错过序列中某些部分的信息。从人类记忆的角度来看,一个事件可能不会在长时间内持续地让我们感到惊奇,尽管它是令人难忘的。其原因是,初始时刻的惊奇程度足以在长时间范围内引起我们的注意,从而记住整个时间范围。为了改进上述的惊奇度指标,我们将惊奇度指标分解为两部分:(1)过去惊奇,用于衡量非常近期过去的信息;以及 (2) 当前惊奇,用于衡量新输入数据的惊奇程度:
$$\begin{align}
\mathcal{M}_t &= (1-\alpha_t)\mathcal{M}_{t-1} + \bm{S}_t\\
\bm{S}_t & = \eta_t\underbrace{\bm{S}_{t-1}}_{过去惊奇} - \theta_t\underbrace{\nabla\ell(\mathcal{M}_{t-1},\bm{x}_t)}_{当前惊奇}
\end{align}$$
有趣的是,这种形式与带有动量的梯度下降相似,其中 $\bm{S}_t$是动量项。因此,这里的动量起到了跨时间(序列长度)的“惊奇”记忆作用。在该形式中, $\eta_t$ 是一个数据依赖的惊讶衰减项( $\bm{x}_t$的函数),控制惊讶随时间的衰减程度,而 $\theta_t$ 则控制应将多少即时惊奇纳入最终的惊奇度量中,以数据依赖的方式进行。这种数据依赖性在该设计中尤为重要:虽然前一个标记的惊奇可能需要影响下一个标记的惊讶,但如果所有标记都相关且处于同一上下文中,这种做法才大多有效。因此,一个数据依赖的 $\eta$ 可以控制是否需要保留记忆:(1) 通过设置 $\eta_t\to 0$ 忽略最后的惊讶(可能由于上下文的变化),或(2) 通过设置 $\eta_t\to 1$ 完全保留最后的惊讶(可能因为该标记与其最近的前序标记高度相关)。 $\alpha_t \in [0,1]$ 是控制记忆的门控机制;即决定应遗忘多少信息。例如,它可以通过让 $\alpha_t\to 0$ 来更新记忆而不影响过去的抽象,也可以通过让 $\alpha_t\to 1$ 清除整个记忆。
4.3、统一的解释
在惊奇度定义中,并没有明确 $\mathcal{M}_t$ 和 $\nabla\ell(\mathcal{M}_{t-1},\bm{x}_t)$ 的具体形式。这样就有了设计的空间。 这样 LightningAttention、GLA、Mamba、HGRN2、DeltaNet、RWKV-7、TTT、GatedDeltaNet、Titans-LMM就只是$\mathcal{M}_t$ 和 $\nabla\ell(\mathcal{M}_{t-1},\bm{x}_t)$的不同而已。以上就是Titans的解释。
五、Miras的统一框架
与Titans的不同,Miras更进一步:定义目标函数,再做梯度更新太麻烦。直接一步到位的最大化一个统一的目标函数,理论上是更加简洁,更具有通用性。与Titans依赖“惊奇”启发式设计不同,Miras[^7]认为:所有的记忆更新,本质上是求解一个在线凸优化问题。它能够将DeltaNet、RWKV-7、Gated DeltaNet、TTT等一系列现代RNN的状态更新统一在同一优化框架下。
5.1、从梯度下降到近端正则化
目标函数优化的梯度更新等价于线性近似加参数正则约束目标(Constrained Approximation)的优化。也就是说 $\displaystyle \min_{\bm{S}} \ell(\bm{S})$,执行梯度下降有 $\bm{S}_{t}= \bm{S}_{t-1}-\beta_t\nabla\ell(\bm{S}_t)$,可以使用如下优化目标函数代替:
$$\begin{align}
\min_{\bm{x}} \tilde{\ell}(\bm{S})=[\bm{S}-\bm{S}_{t-1}]^\T\nabla_\bm{S} \ell(\bm{S})+\frac{1}{2\beta_t}|\bm{S}-\bm{S}_t|_F^2
\end{align}$$
容易知道 $\nabla\tilde{\ell}(\bm{S})=0$可得:
$$\begin{align}
&\nabla \ell(\bm{S}_t) + \frac{1}{\beta_t}(\bm{S}-\bm{S}_{t-1})=0\\
\Leftrightarrow&\bm{S} = \bm{S}_{t-1} - \beta_t\nabla_\bm{S} \tilde{\ell}(\bm{S}_t)
\end{align}$$
这样把梯度更新的问题,转化为了一个最优化问题。实际上有内积符号 $\langle\cdot,\cdot\rangle$, 这样就有优化目标
$$\begin{align}
\tilde{\ell}(\bm{S})
=\langle \bm{S}-\bm{S}_{t-1},\nabla\ell(\bm{S})\rangle+\frac{1}{2\beta_t}|\bm{S}-\bm{S}_t|_F^2
\end{align}$$
这种单步梯度下降可以等价地转化为一个近端正则化问题:在 $\bm{S}_{t-1}$ 附近寻找一个点,使其在损失函数的一阶近似下表现良好,同时用二次正则项惩罚对旧状态的偏离。准确地说,梯度下降是如下优化问题的闭式解:
$$\begin{align}
\bm{S}_{t} = \arg\min_{\bm{S}} \; \underbrace{\langle \bm{S} - \bm{S}_{t-1}, \nabla\ell(\bm{S}_{t-1}) \rangle}_{\text{局部损失近似}} \; + \; \frac{1}{2\beta_t}|\bm{S} - \bm{S}_{t-1}|_F^2
\end{align}$$
这一目标函数的一阶最优条件恰好给出 $\nabla\ell(\bm{S}_{t-1}) + \frac{1}{\beta_t}(\bm{S} - \bm{S}_{t-1}) = 0$,即梯度下降更新。沿着这种思路,我们不再需要显式地计算梯度,而是直接定义一类更广义的优化问题来更新记忆。
5.2、统一性的数学基础
在Miras的统一视角下,一切记忆更新皆可归结为在线凸优化的不同实例。这一论断的数学根基是“跟随正则化引导者”(FTRL)视角与“学习-保留”视角的等价性。这里我们将完全展开每一步推导,并先清晰界定两种视角的具体形式。
5.2.1、定义:FTRL视角
上述目标函数可视为在损失函数序列上执行的一步在线梯度下降:
$$\begin{align}
\ell(\bm{W};\bm{k}_1,\bm{v}_1) , \ell(\bm{W};\bm{k}_2,\bm{v}_2), \ldots , \ell(\bm{W};\bm{k}_t,\bm{v}_t),\ldots
\end{align}$$
众所周知,在线梯度下降可视为跟随正则化引导者FTRL(Follow-The-Regularized-Leader )算法在特定损失函数选择下的特例(Shalev-Shwartz et al. 2012, Chapter 2; Hazan et al. 2016)。具体而言,若假设 $\bm{S}_0= \bm{0}$,则更新规则等价于给定到目前为止的所有键值对 $(\bm{k}_1,\bm{v}_1),\dots,(\bm{k}_t,\bm{v}_t)$,记忆参数 $\bm{S}$ 通过同时最小化所有过往损失与一个正则项来更新:
$$\begin{align}
\widehat{\bm{S}}_t = \arg\min_{\bm{S}\in\mathcal{W}}\left\{\sum_{i=1}^{t} \widehat{\ell}_i(\bm{S}; \bm{k}_i, \bm{v}_i) \; + \; \frac{1}{\eta} R(\bm{S}) \right\}
\end{align}$$
其中:
- $\widehat{\ell}_i(\cdot)$ 是某个衡量在第 $i$ 个样本上表现的损失函数(或其近似)。
- $R(\bm{S})$ 是一个不随时间变化的凸正则化函数(如 $L_2$ 范数)。
- $\eta > 0$ 是全局学习率,此处假定为常数(命题3.2的前提)。
- $\mathcal{W}$ 为参数空间,命题中取 $\mathcal{W} = \mathbb{R}^d$(无约束)。
由 (FTRL) 生成的记忆参数序列记为 $\{\widehat{\bm{S}}_1, \widehat{\bm{S}}_2, \dots\}$。
5.2.2、学习-保留视角
学习-保留视角则将记忆更新拆解为两个对抗力量的平衡:适应新样本(注意偏置) 与 保护旧记忆(保留机制)。其一般形式为:
$$\begin{align}
\widetilde{\bm{S}}_t = \arg\min_{\bm{S} \in \mathcal{W}} \left\{\widetilde{\ell}_t(\bm{S};\bm{k}_t, \bm{v}_t) \; + \; \mathrm{Ret}_t(\bm{S}, \widetilde{\bm{S}}_{t-1}) \right\}
\end{align}$$
有命题建立学习-保留视角与跟随正则化引导等价,对其中两项做了特定选择:
- 1、注意偏置 $\widetilde{\ell}_t$ 直接取为 FTRL 中的损失函数:$\widetilde{\ell}_t(\cdot) = \widehat{\ell}_t(\cdot)$。
- 2、保留函数 $\mathrm{Ret}_t(\bm{S}, \bm{S}’)$ 取为布雷格曼散度 $\mathcal{D}_{h_t}(\bm{S}, \bm{S}’)$,该散度由函数 $h_t$ 生成,而 $h_t$ 又恰好是 FTRL 中截至 $t-1$ 步的历史代价:
$$\begin{align}
h_t(\bm{S}) := \sum_{i=1}^{t-1} \widehat{\ell}_i(\bm{S}; \bm{k}_i, \bm{v}_i) + \frac{1}{\eta} R(\bm{S})
\end{align}$$
布雷格曼散度的定义为:
$$\begin{align}
\mathcal{D}_{h_t}(\bm{S}, \bm{S}’) = h_t(\bm{S}) - h_t(\bm{S}’) - \langle \nabla h_t(\bm{S}’), \bm{S} - \bm{S}’ \rangle
\end{align}$$
它衡量用 $\bm{S}’$ 处的一阶泰勒展开近似 $h_t(\bm{S})$ 时产生的误差,是一种广义的“距离”。
于是,学习-保留视角下的序列 $\{\widetilde{\bm{S}}_t\}$ 由下式生成:
$$\begin{align}
\widetilde{\bm{S}}_t = \arg\min_{\bm{S}} \Big\{ \underbrace{\widehat{\ell}_t(\bm{S}; \bm{k}_t, \bm{v}_t)}_{\text{注意偏置}} \; + \; \underbrace{\mathcal{D}_{h_t}(\bm{S}, \widetilde{\bm{S}}_{t-1})}_{\text{保留}} \Big\}
\end{align}$$
我们的目标是:若两序列初始相同,则对所有 $t$ 有 $\widetilde{\bm{S}}_t = \widehat{\bm{S}}_t$。下面用数学归纳法给出严格证明:
5.2.3、跟随正则化引导与学习-保留框架等价性证明
1. 归纳基础
假设两个过程从同一初始点 $W_0$ 启动。由 (FTRL) 得 $\widehat{\bm{S}}_1 = \arg\min_{\bm{S}} \big\{ \widehat{\ell}_1(\bm{S}) + \frac{1}{\eta}R(\bm{S}) \big\}$。
对于学习-保留视角,$t=1$ 时 $h_1(\bm{S}) = \frac{1}{\eta}R(\bm{S})$(求和为空)。于是
$$\begin{align}
\mathcal{D}_{h_1}(\bm{S}, \bm{S}_0) = h_1(\bm{S}) - h_1(\bm{S}_0) - \langle \nabla h_1(\bm{S}_0), \bm{S} - \bm{S}_0 \rangle
\end{align}$$
代入 (3),并去掉常数项 $-h_1(\bm{S}_0) - \langle \nabla h_1(\bm{S}_0), -\bm{S}_0 \rangle$,得
$$\begin{align}
\widetilde{\bm{S}}_1 = \arg\min_{\bm{S}} \big\{ \widehat{\ell}_1(\bm{S}) + h_1(\bm{S}) - \langle \nabla h_1(\bm{S}_0), \bm{S} \rangle \big\}
\end{align}$$
通常可令 $\bm{S}_0 = \bm{0}$ 且 $R(\bm{0})=\bm{0}$,若 $R$ 在零点梯度也为 $\bm{0}$,则 $\nabla h_1(\bm{S}_0) = \frac{1}{\eta}\nabla R(\bm{0})=\bm{0}$,于是上式退化为 $\widehat{\ell}_1(\bm{S}) + \frac{1}{\eta}R(\bm{S})$,与 $\widehat{\bm{S}}_1$ 的目标一致,因此 $\widetilde{\bm{S}}_1 = \widehat{\bm{S}}_1$。若初始点非零点,可通过令 $h_1(\bm{S})$ 包含初始正则化项或调整定义来保证等价性——命题的核心在递推步骤,基础通常自然成立。我们可不失一般性地假设 $\widetilde{\bm{S}}_1 = \widehat{\bm{S}}_1$ 。
2. 归纳假设
假设对某个 $t-1 \geqslant 1$,已有
$$\begin{align}
\widetilde{\bm{S}}_{t-1} = \widehat{\bm{S}}_{t-1}
\end{align}$$
3. 归纳步骤(证明 $\widetilde{\bm{S}}_t = \widehat{\bm{S}}_t$)
由学习-保留视角的更新式和散度展开式:
$$
\begin{aligned}
\widetilde{\bm{S}}_t
&= \arg\min_{\bm{S}} \Big\{ \widehat{\ell}_t(\bm{S}) \;+\; h_t(\bm{S}) - h_t(\widetilde{\bm{S}}_{t-1}) - \langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \bm{S} - \widetilde{\bm{S}}_{t-1} \rangle \Big\} \\
&= \arg\min_{\bm{S}} \Big\{ \widehat{\ell}_t(\bm{S}) + h_t(\bm{S}) - \langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \bm{S} \rangle \\
&\qquad\qquad\qquad + \underbrace{\big[ -h_t(\widetilde{\bm{S}}_{t-1}) + \langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \widetilde{\bm{S}}_{t-1} \rangle \big]}_{\text{与 } \bm{S} \text{ 无关的常数}} \Big\}.
\end{aligned}
$$
移除常数项,优化目标变为:
$$\begin{align}
\widetilde{\bm{S}}_t = \arg\min_{\bm{S}} \Big\{ \widehat{\ell}_t(\bm{S}) + h_t(\bm{S}) - \langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \bm{S} \rangle \Big\}
\end{align}$$
现在将 $h_t(\bm{S})$ 的定义 (1) 代入:
$$\begin{align}
\widehat{\ell}_t(\bm{S}) + h_t(\bm{S}) = \widehat{\ell}_t(\bm{S}) + \sum_{i=1}^{t-1} \widehat{\ell}_i(\bm{S}) + \frac{1}{\eta} R(\bm{S})
= \sum_{i=1}^{t} \widehat{\ell}_i(\bm{S}) + \frac{1}{\eta} R(\bm{S})
\end{align}$$
于是 (5) 变为:
$$\begin{align}
\widetilde{\bm{S}}_t = \arg\min_{\bm{S}} \left\{ \sum_{i=1}^{t} \widehat{\ell}_i(\bm{S}) + \frac{1}{\eta} R(\bm{S}) \;-\; \langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \bm{S} \rangle \right\}
\end{align}$$
关键一步:利用归纳假设 (4),$\widetilde{\bm{S}}_{t-1} = \widehat{\bm{S}}_{t-1}$。因此梯度项可以改写:
$$
\nabla h_t(\widetilde{\bm{S}}_{t-1}) = \nabla h_t(\widehat{\bm{S}}_{t-1})
$$
但 $\widehat{\bm{S}}_{t-1}$ 正是 FTRL 视角在第 $t-1$ 步的解,即
$$
\widehat{\bm{S}}_{t-1} = \arg\min_{\bm{S}} \Big\{ \sum_{i=1}^{t-1} \widehat{\ell}_i(\bm{S}) + \frac{1}{\eta} R(\bm{S}) \Big\} = \arg\min_{\bm{S}} h_t(\bm{S})
$$
因为 $h_t(\bm{S})$ 严格凸且定义域为全空间 $\mathbb{R}^d$,该无约束优化问题在最小值点 $\widehat{\bm{S}}_{t-1}$ 处梯度为零:
$$
\nabla h_t(\widehat{\bm{S}}_{t-1}) = \bm{0}
$$
将 (8) 代入 (7),内积项 $\langle \bm{0}, W \rangle = 0$,目标函数简化为:
$$
\widetilde{\bm{S}}_t = \arg\min_{\bm{S}} \left\{ \sum_{i=1}^{t} \widehat{\ell}_i(\bm{S}) + \frac{1}{\eta} R(W) \right\}
$$
而式 (9) 的右边正是 FTRL 视角对 $\widehat{\bm{S}}_t$ 的定义。因此
$$
\widetilde{\bm{S}}_t = \widehat{\bm{S}}_t
$$
4. 归纳完成
由归纳原理,对所有 $t \ge 1$ 均有 $\widetilde{\bm{S}}_t = \widehat{\bm{S}}_t$,即两个视角产生的记忆更新序列完全一致。
个人评述
这个证明的核心在于“构造”了一个巧妙的保留函数——布雷格曼散度 $\mathcal{D}_{h_t}$。当将基于该散度的“学习-保留”优化目标展开后,历史损失的信息通过 $h_t(W)$ 被自然引入,而一阶内积项 $\langle \nabla h_t(\widetilde{\bm{S}}_{t-1}), \bm{S} \rangle$ 恰好因 FTRL 前一步的最优性而消失。这就使得“在新数据上学习+靠近旧状态”的局部操作,精妙地等价于“重新求解整个历史序列损失加正则”的全局操作。换言之,只要保留机制选择为历史累积损失的布雷格曼散度,局部记忆更新就能忠实地模拟全局重演。这一结论为Miras将各类RNN状态更新统一为注意偏置与保留机制的不同实例提供了坚实的理论基座。
5.3 从学习-保留到统一框架
已经证明在温和的凸性假设下,学习-保留视角与FTRL(跟随正则化引导者)视角是等价的。这为我们提供了统一众多模型的钥匙。现在,我们将这一等价性具体化为Miras的统一框架:任何线性RNN的记忆更新,都可以写成如下形式的“学习-保留”优化问题
$$\begin{align}
\boxed{
\bm{S}_{t} = \arg\min_{\bm{S}} \;
\underbrace{\widetilde{\ell}_t(\bm{S}; \bm{k}_t, \bm{v}_t)}_{\text{注意偏置(学习新信息)}} \; + \;
\underbrace{\operatorname{Ret}_t(\bm{S}, \bm{S}_{t-1})}_{\text{保留机制(巩固旧记忆)}}
}
\end{align}$$
其中,$\widetilde{\ell}_t$ 是瞬时损失 $\ell_t$ 的某种近似,而 $\operatorname{Ret}_t$ 控制对前一时刻状态 $\bm{S}_{t-1}$ 的偏离程度,并可进一步分解为局部保留和全局保留部分:
$$
\operatorname{Ret}_t(\bm{S}, \bm{S}_{t-1}) = \frac{1}{\eta_t} D_t(\bm{S}, \bm{S}_{t-1}) \; + \; \frac{1}{\alpha_t} G_t(\bm{S}). \tag{5.3}
$$
不同的模型实质上就是对近似损失 $\widetilde{\ell}_t$、局部散度 $D_t$、全局正则项 $G_t$ 以及元学习率 $\eta_t,\alpha_t$ 做出不同选择的结果。下面我们以几个典型模型为例,展示它们如何被嵌入这一框架。
5.3.1、原始线性注意力(Hebb学习规则)
取瞬时损失 $\ell(\bm{S}) = -\langle \bm{S}, \bm{k}_t\bm{v}_t^\T \rangle$ (旨在最大化输入键值对的内积),并令 $D_t(\bm{S},\bm{S}_{t-1}) = \frac{1}{2}|\bm{S} - \bm{S}_{t-1}|_F^2$,不设全局保留项。此时,(5.2)的解析解为:
$$
\bm{S}_{t} = \bm{S}_{t-1} + \eta_t \bm{v}_t\bm{k}_t^\T,
$$
即Hebb加性更新。
5.3.2、DeltaNet
使用平方误差的线性化近似:$\widetilde{\ell}_t(\bm{S}) = \bm{\beta}_t\langle \bm{S} - \bm{S}_{t-1}, \nabla\ell(\bm{S}_{t-1}) \rangle$,其中 $\nabla\ell(\bm{S}_{t-1}) = \bm{S}_{t-1}\bm{k}_t\bm{k}_t^\T - \bm{v}_t\bm{k}_t^\T$,并采用二次局部保留 $D_t(\bm{S},\bm{S}_{t-1}) = \frac{1}{2}|\bm{S} - \bm{S}_{t-1}|_F^2$,得到优化目标:
$$\begin{align}
\min_{\bm{S}}
\bm{\beta}_t\langle \bm{S} - \bm{S}_{t-1}, \nabla\ell(\bm{S}_{t-1}) \rangle+
\frac{1}{2}|\bm{S} - \bm{S}_{t-1}|_F^2
\end{align}$$
为了求解 $\bm{S}_t$,我们需要对目标函数关于 $\bm{S}$ 求导,并令其等于零。
第一步:展开目标函数
利用矩阵内积与 Frobenius 范数的性质 $\langle \bm{A}, \bm{B} \rangle = \mathrm{Tr}(\bm{A}^\T \bm{B})$ 和 $|\bm{A}|_F^2 = \mathrm{Tr}(\bm{A}^\T \bm{A})$,目标函数可以写为:
$$\begin{align}
J(\bm{S}) = \bm{\beta}_t\mathrm{Tr}((\bm{S} - \bm{S}_{t-1})^\T \nabla\ell(\bm{S}_{t-1})) + \frac{1}{2} \mathrm{Tr}((\bm{S} - \bm{S}_{t-1})^\T (\bm{S} - \bm{S}_{t-1}))
\end{align}$$
第二步:对 $\bm{S}$ 求导
利用矩阵求导法则:1. $\frac{\partial}{\partial \bm{X}} \mathrm{Tr}(\bm{X}^\T \bm{A}) = \bm{A}$; 2. $\frac{\partial}{\partial \bm{X}} \mathrm{Tr}((\bm{X} - \bm{B})^\T (\bm{X} - \bm{B})) = 2(\bm{X} - \bm{B})$,对 $J(\bm{S})$ 关于 $\bm{S}$ 求导,得到:
$$\begin{align}
\frac{\partial J(\bm{S})}{\partial \bm{S}} = \bm{\beta}_t\nabla\ell(\bm{S}_{t-1}) + (\bm{S} - \bm{S}_{t-1})
\end{align}$$
第三步:令导数为零$\frac{\partial J(\bm{S})}{\partial \bm{S}} = \bm{0}$,并求解 $\bm{S}_t$得:
$$\begin{align}
\bm{\beta}_t\nabla\ell(\bm{S}_{t-1}) + \bm{S}_t - \bm{S}_{t-1} = \bm{0}
\end{align}$$
移项即可得到 $\bm{S}_t$ 的更新规则(本质上是步长为 1 的梯度下降):
$$\begin{align}
\bm{S}_t = \bm{S}_{t-1} - \bm{\beta}_t\nabla\ell(\bm{S}_{t-1})
\end{align}$$
第四步:代入给定的梯度表达式 已知 $\nabla\ell(\bm{S}_{t-1}) = \bm{S}_{t-1}\bm{k}_t\bm{k}_t^\T - \bm{v}_t\bm{k}_t^\T$,代入上式:
$$\begin{align}
\bm{S}_t = \bm{S}_{t-1} - \bm{\beta}_t(\bm{S}_{t-1}\bm{k}_t\bm{k}_t^\T - \bm{v}_t\bm{k}_t^\T)
\end{align}$$
第五步:整理得到最终结果 将 $\bm{S}_{t-1}$ 提取公因式,得到 DeltaNet 的标准递推形式:
$$\begin{align}
\bm{S}_{t}
= \bm{S}_{t-1}(\bm{E} - \beta_t \bm{k}_t\bm{k}_t^\T) + \beta_t \bm{v}_t\bm{k}_t^\T
\end{align}$$
5.3.3、RWKV-7的状态更新
RWKV-7引入了数据依赖的衰减和向量化学率,它的记忆更新机制很精细:
$$\begin{align}
\bm{S}_t= \bm{S}_{t-1}\big[\mathrm{diag}[\bm{w}_t]-\bm{\kappa}_t(\bm{\beta}_t\odot\bm{\kappa}_t)^\T\big]+ \bm{v}_t(\bm{\eta}_t\odot\bm{k}_t)^\T
\end{align}$$
其中 $\bm{\kappa}_t=\bm{k}_t\odot \bm{\xi}$。如何用 Miras的统一框架的目标函数理解,需要费点神。
1、注意力偏置(学习新信息) $\widetilde{\ell}_t(\bm{S}) = \langle \bm{S} - \bm{S}_{t-1}, \nabla\ell(\bm{S}_{t-1}) \rangle$,这个没有变化。区别在于 $\ell(\bm{S}_{t-1})$, RWKV对于记忆写入加入了调制,其中 $\bm{k}_{write} = \bm{\eta}_t\odot\bm{k}_t$,用 $\bm{\eta}_t$控制。
$$\begin{align}
\ell(\bm{S}_{t-1}) = \underbrace{\frac{1}{2}|\bm{S}_{t-1}\bm{k}_{write} - \bm{v}_t|_F^2}_{\text{写入对齐}}
\end{align}$$
2、保留项 $\mathrm{Ret}_t(\bm{S}, \bm{S}_{t-1})$,分为两个部分局部保留 $D_t(\bm{S},\bm{S}_{t-1})$和全局保留 $G_t(\bm{S})$。
- 局部保留 $D_t(\bm{S},\bm{S}_{t-1})$
$$\begin{align}
D_t(\bm{S},\bm{S}_{t-1}) = \underbrace{\frac{1}{2}\left|\bm{S} - \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t)\right|_F^2}_{\text{近端约束}}
\end{align}$$
- 全局保留 $G_t(\bm{S})$, 使用加权范数控制遗忘,Frobenius 范数控制写入, 其中$\bm{k}_{write}=\bm{\kappa}_t = \bm{\xi}\odot \bm{k}_t$具体如下:
$$\begin{align}
G_t(\bm{S}) =
\underbrace{\frac{1}{2}|\bm{S}\bm{k}_{forget}|_{\mathrm{diag}(\bm{\beta}_t)}^2}_{\text{定向遗忘}} -
\underbrace{\frac{1}{2}|\bm{S}\bm{k}_{write}|_F^2}_{\text{写入保护}}
\end{align}$$
RWKV的记忆目标函数就是
$$\begin{align}\min_{\bm{S}} \underbrace{\langle \bm{S} - \bm{S}_{t-1}, \nabla\ell(\bm{S}_{t-1}) \rangle \vphantom{\frac{1}{2}\left|\bm{S}\right|_F^2}}_{\text{注意力偏置 (写入一阶近似)}}+ \underbrace{\frac{1}{2}\left|\bm{S} - \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t)\right|_F^2}_{\text{局部保留 (近端约束)}}+ \underbrace{\langle\bm{S} - \bm{S}_{t-1}, \nabla G_t(\bm{S}_{t-1}) \rangle \vphantom{\frac{1}{2}\left|\bm{S}\right|_F^2}}_{\text{全局保留 (遗忘与写入一阶近似)}}
\end{align}
$$
其中:
基础损失梯度:$\nabla\ell(\bm{S}_{t-1}) = \bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T - \bm{v}_t\bm{k}_{write}^\T$
全局保留的梯度:$\nabla G_t(\bm{S}_{t-1}) = \bm{S}_{t-1}\bm{k}_{forget}(\bm{\beta}_t\odot\bm{k}_{forget})^\T - \bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T$
对目标函数关于 $\bm{S}$ 求导,并令其为零:
$$\begin{align}
\nabla\ell(\bm{S}_{t-1}) + \nabla G_t(\bm{S}_{t-1}) + (\bm{S}_t - \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t)) = \bm{0}
\end{align}$$
解出 $\bm{S}_t$ :
$$\begin{align}
\bm{S}_t = \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t) - \big[ \nabla\ell(\bm{S}_{t-1}) + \nabla G_t(\bm{S}_{t-1}) \big]
\end{align}$$
代入两个梯度的具体表达式:
$$
\begin{aligned}
\bm{S}_t &= \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t) - \big[ (\bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T - \bm{v}_t\bm{k}_{write}^\T) + (\bm{S}_{t-1}\bm{k}_{forget}(\bm{\beta}_t\odot\bm{k}_{forget})^\T - \bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T) \big] \\
&= \bm{S}_{t-1}\mathrm{diag}(\bm{w}_t) - \bm{S}_{t-1}\bm{k}_{forget}(\bm{\beta}_t\odot\bm{k}_{forget})^\T + \bm{v}_t\bm{k}_{write}^\T
\underbrace{- \bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T + \bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T}_{\text{完美抵消!}}
\end{aligned}
$$
得到最终结果:
$$\bm{S}_t = \bm{S}_{t-1}\big[\mathrm{diag}(\bm{w}_t) - \bm{\kappa}_t(\bm{\beta}_t\odot\bm{\kappa}_t)^\T\big] + \bm{v}_t(\bm{\eta}_t\odot\bm{k}_t)^\T$$
可以看到
1、二次型惩罚是硬约束:如果使用 $\frac{1}{2}|\bm{S}\bm{k}_{forget}|^2$,而不是 $\langle \bm{S} - \bm{S}_{t-1}, \nabla G_t \rangle$,它的物理意义是“我要求 $\bm{S}_t$ 在 $\bm{k}_{forget}$ 方向上的能量必须小”。这会压榨 $\bm{S}_t$ 的空间,导致新信息 $\bm{v}_t\bm{k}_{write}^\T$ 难以写入,这个时候在求解 $\bm{S}_t$就必须引入复杂的矩阵求逆(隐式更新)才能平衡。
2、线性偏置是软推力:使用 $\langle \bm{S} - \bm{S}_{t-1}, \nabla G_t \rangle$,它的物理意义是“我不管 $\bm{S}_t$ 最终长什么样,我只是沿着当前估算的梯度 $\nabla G_t$ 推它一把”。
3、写入保护的本质:在梯度相加时,$\nabla\ell$ 中的 $+\bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T$ 和 $\nabla G_t$ 中的 $-\bm{S}_{t-1}\bm{k}_{write}\bm{k}_{write}^\T$ 完美抵消。这说明,“写入保护”的本质,就是提供一个与“写入对齐”方向相反的梯度推力,用来抵消基础损失试图无限制拉扯旧状态的趋势,从而为真正的信息写入 $\bm{v}_t\bm{k}_{write}^\T$ 腾出干净的更新空间。
总的来说,RWKV-7 的精细门控并非来自对最终状态的复杂二次惩罚,而是来自对更新方向(梯度)的精细拆解与抵消。
5.3.4、Attention(注意力机制)
正如 Sun et al. (2024) 所指出,softmax 注意力是 MSE 损失函数(即 )的非参数解,对应于 Nadaraya-Watson 估计器。因此,当我们使用 Nadaraya-Watson 估计器找到 MSE 损失的非参数解,且不使用任何保持项(retention)时,softmax 注意力就是 Miras 框架的一个特例。知乎已有很多文章解释注意力机制和Nadaraya-Watson的核回归的关系,这里不在赘述。
5.4 Miras评述
Miras框架的精妙之处在于:将看似启发式的记忆更新解耦为两个正交的设计维度——如何从新样本中学习(注意偏置),以及如何保护旧知识(保留机制)。这不仅为DeltaNet、RWKV-7等模型提供了严格的数学解释,更指明了未来创新的方向:
- 改进注意偏置 $\widetilde{\ell}_t$:可以设计更贴近实际任务损失的近似,例如对比损失、自适应惊奇度量等。
- 设计保留机制 $\operatorname{Ret}_t$:可以在布雷格曼散度的框架下,引入结构化的局部与全局正则,实现更精细的记忆控制,如选择性遗忘、层级记忆压缩等。
- 元学习率 的数据依赖化:$\eta_t, \alpha_t$ 可被小型网络动态预测,实现上下文感知的记忆持久性,这正是RWKV-7等模型已经验证有效的路径。
通过优化视角重新审视循环神经网络的记忆,我们已将“记忆”从一个经验概念提升为一种可设计、可分析、可优化的数学对象。
六、RWKV的Emdbed改造
6.1、Mixture of Lookup Experts的探索
FFN层一般认为是存储知识的地方,原则上也可以认为是记忆,FFN的计算量也相当可观,如果FFN能变成数据库直接查询知识,岂不妙哉?MoLE(Mixture of Lookup Experts)[^9]就是这样的。相对于 MOE的 FFN,在 MoLE中,FFN 接收的是共享的词表 Embedding,而不是前面任意层的隐藏向量,但因为每一层的 FFN 专家权重是独立的,所以可以按层独立重参数化生成的 Lookup Table(查找表)。MoLE 的机制:共享输入 Embedding + 独立的 FFN 权重 → 独立的 LUT
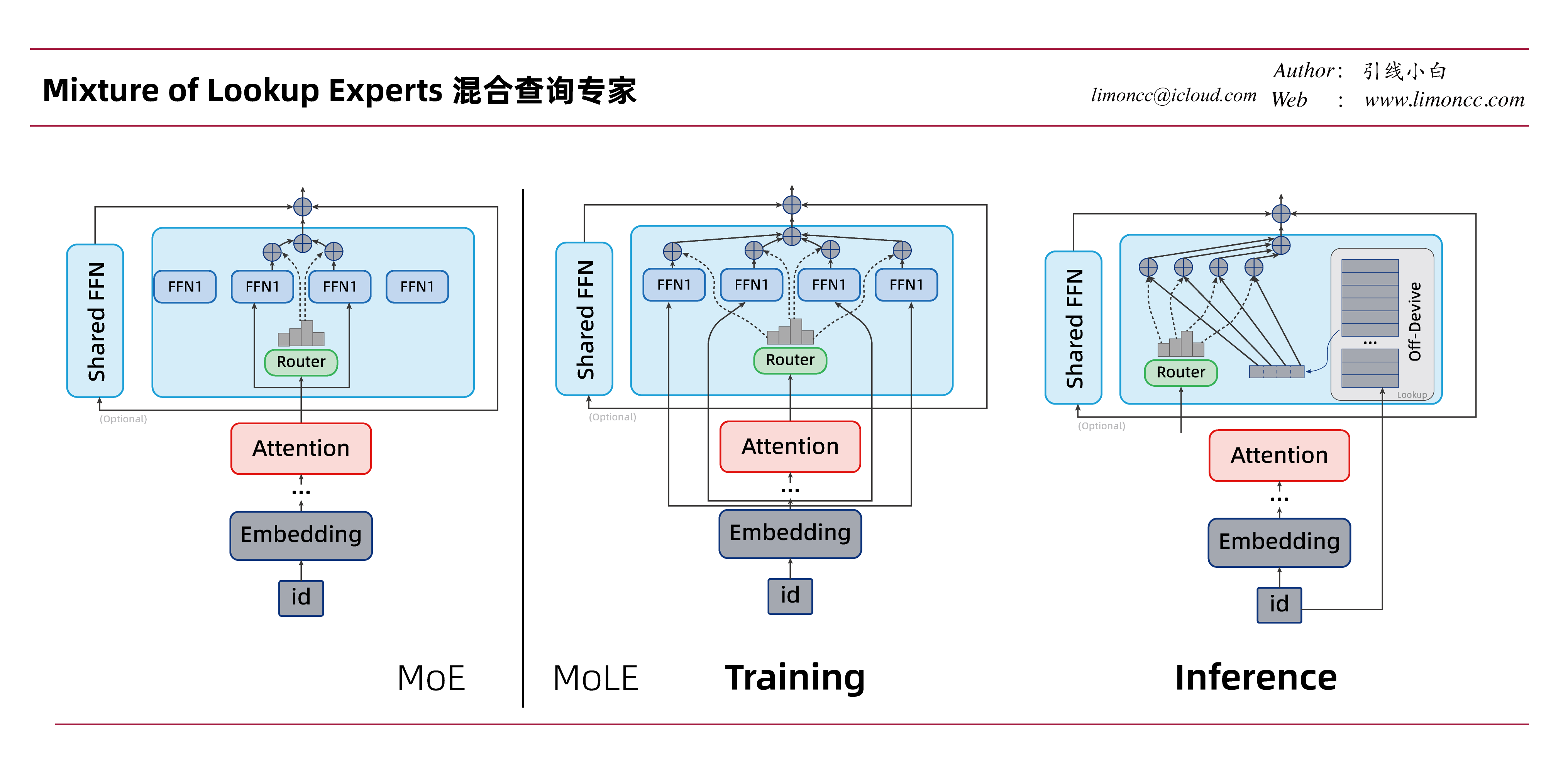
传统 MoE
每一层的输出 $\bm{y}$ 由隐藏状态 $\bm{x}$ 和多个专家 $E_i$ 决定:
$$\begin{align}
\bm{y} = \sum_{i} g_i(\bm{x}) E_i(\bm{x})
\end{align}$$
这里的 $\bm{x}$ 是当前层的隐藏状态,每层不同,且随上下文变化,因此无法提前计算。
MoLE 的改造
强制专家的输入只能是原始的词表 Embedding $e_{token}$,而不是隐藏状态 $\bm{x}$。路由器 $g$ 依然依赖于上下文 $\bm{x}$, 其中输入的 Embedding就是模型第一层那个固定的词表嵌入向量,所有层、所有专家接收的同名 token 的输入是同一个向量。FFN 专家是按层独立的:第 $l$ 层的专家 $E_i^{(l)}$ 拥有自己独立的参数,所以依然是可学习的。
$$\begin{align}
\bm{y} = \sum_{i} g_i(\bm{x}) E_i(e_{token})
\end{align}$$
在推理阶段,按层独立生成的 LUT :因为 $E_i^{(l)}$ 每层不同,所以同一个 token 在不同层经过专家计算后的输出也不同。预计算时,必须为每一层单独建一个查找表:
$$\begin{align}
LUT^{(l)}[token_id, expert_id] = E_i^{(l)}(e_{token})
\end{align}$$
MoLE本质上是用共享的 Embedding 去查询各层独立的 FFN,它的 LUT 是 FFN推理结果的离线缓存。
6.2、RWKV的DeepEmdbed
RWKV 的DeepEmbed 则完全抛弃了“FFN 专家”的壳,走向了更简洁的稀疏设计。DeepEmbed:直接在每一层的 FFN 旁边,挂载一个独立的、可学习的 Embedding层。
$$\begin{align}
\bm{y} = \mathrm{FFN}(\bm{x}) \odot Emb^{(l)}(token_id)
\end{align}$$
1、没有共享输入的限制:FFN 的主干的输入依然是上一层的隐藏状态 $x$,保留了模型对上下文的深度非线性变换能力。
2、每层拥有独立的 Embedding 表:第 $l$ 层的 $Emb^{(l)}$ 与第 $m$ 层的 $Emb^{(m)}$ 参数完全独立,直接作为该层的私有参数存在。
3、无需预计算 LUT:它本身就是一个 Embedding 层,推理时直接根据 token_id查表得到向量,然后与 FFN 的输出做逐元素乘法(Channel-wise Scaling)。
DeepEmbed 本质上是“为每一层独立分配一组可学习的 Token 向量”,它不是 FFN 的缓存,而是直接作为乘性偏置参与计算。 它不改动主干 $\mathrm{FFN}(\bm{x})$,而是给模型“外挂”了一个巨大的知识库。在 FFN 算力已经够用、但知识容量不够用”的场景下,提供一种比扩大 FFN 维度性价比高得多的扩容方案。用少量的额外计算(查表) + 系统内存的存储空间,换取了模型参数容量的大幅提升。
6.3、RWKV的AttenDeepEmdbed(DEA)
DeepEmbedAttention (DEA)是 RWKV-v7b在 DeepEmbed 基础上,对注意力侧的扩展。DeepEmbed 只在 FFN 通路 做 token-dependent 缩放,而DEA 则进一步在 Q/K/V 通路 引入基于 token id 的查表向量,对注意力计算进行调制。目标:让注意力机制对 token 的语义/类别更敏感,而不是只依赖隐层表示。
在 RWKV-v7b 的演示代码中,可以看到 DEA 的关键实现:
1 | for i in range(self.n_layer): |
其中 ctx 是 token index 序列(历史 token id 序列),z[qkv+’k_emb.weight’] 和 z[qkv+’v_emb.weight’] 就是基于 token id 的查表嵌入(k_emb / v_emb)。上述实现将RWKV的时间混合和 DEA 调制耦合在一起了,不是很好懂,说白了就是核心在于:在生成 Key ($\bm{k}$) 和 Value ($\bm{v}$) 之后、参与状态更新之前,引入基于 Token ID 的查表向量进行乘性调制。
定义 DEA 的两个可学习查表矩阵:
$\mathrm{Embed_K} \in \mathbb{R}^{|V| \times d_{model}}$:Key 侧的 DeepEmbed 矩阵。
$\mathrm{Embed_V} \in \mathbb{R}^{|V| \times d_{model}}$:Value 侧的 DeepEmbed 矩阵。
其中,$|V|$ 是词表大小,$d_{model}$ 是隐藏层维度。
$$\begin{align}
\tilde{\bm{k}}_t = \bm{k}_t \odot \mathrm{Embed_K}(t)
\end{align}$$
原本的 $\bm{k}_t$ 决定了当前 token 与哪些上下文相关(即“这个 token 能被谁检索到”)。DEA 的 $\mathrm{Embed_K}$ 向量相当于给每个 token 加了一个固定的、可学习的“身份滤镜”。例如,对于 token “Apple”,它的 $\mathrm{Embed_K}$ 可能在“水果”维度上权重很大,在“科技公司”维度上权重很小。这迫使模型在训练时学会:“当遇到 ‘Apple’ 时,强化其在某些语义通道上的 Key 特征”。
同理,对记忆内容的调制(Value 侧)
$$\begin{align}
\tilde{\bm{v}}_t = \bm{v}_t \odot \mathrm{Embed_V}(t)
\end{align}$$
$\bm{v}_t$ 是当前 token 存入记忆的实际内容。DEA 的 $\mathrm{Embed_V}(t)$ 向量决定了这个 token “以什么姿态”被存储。这相当于给每个 token 的内容赋予了特定的权重分布。比如,遇到数字 token 时,$\mathrm{Embed_V}(t)$ 可能会强化数值处理相关的通道,抑制语义情感通道。
- 每个 token 的 K/V 表示不仅取决于当前隐层 x,还显式依赖该 token 的 id,通过 emb_k / emb_v 进行调整。
- 这相当于在注意力中引入了 token-type / token-semantic 的先验,有利于不同语义类型的 token 使用不同的键值表示。
DeepEmbed 和 DEA 组合从模型视角看,这相当于在 RWKV 的 RNN 循环中,引入了一组按 token 索引寻址的“记忆槽”,既影响当前层的 FFN 计算,也影响跨时间步的注意力传播。
七、RockAI的方案
2025WAIC上的岩芯数智(RockAI)也展示了一种可微的神经网络记忆单元。他们称之为Yan 2.0 Preview, 但并非开源模型,不通过他们公开的构图大致实现思路是清楚的。Yan 2.0 Preview所声称的原生记忆力,不过是线性注意力的机制的MOE版本。笔者重新绘制了架构图,如下:
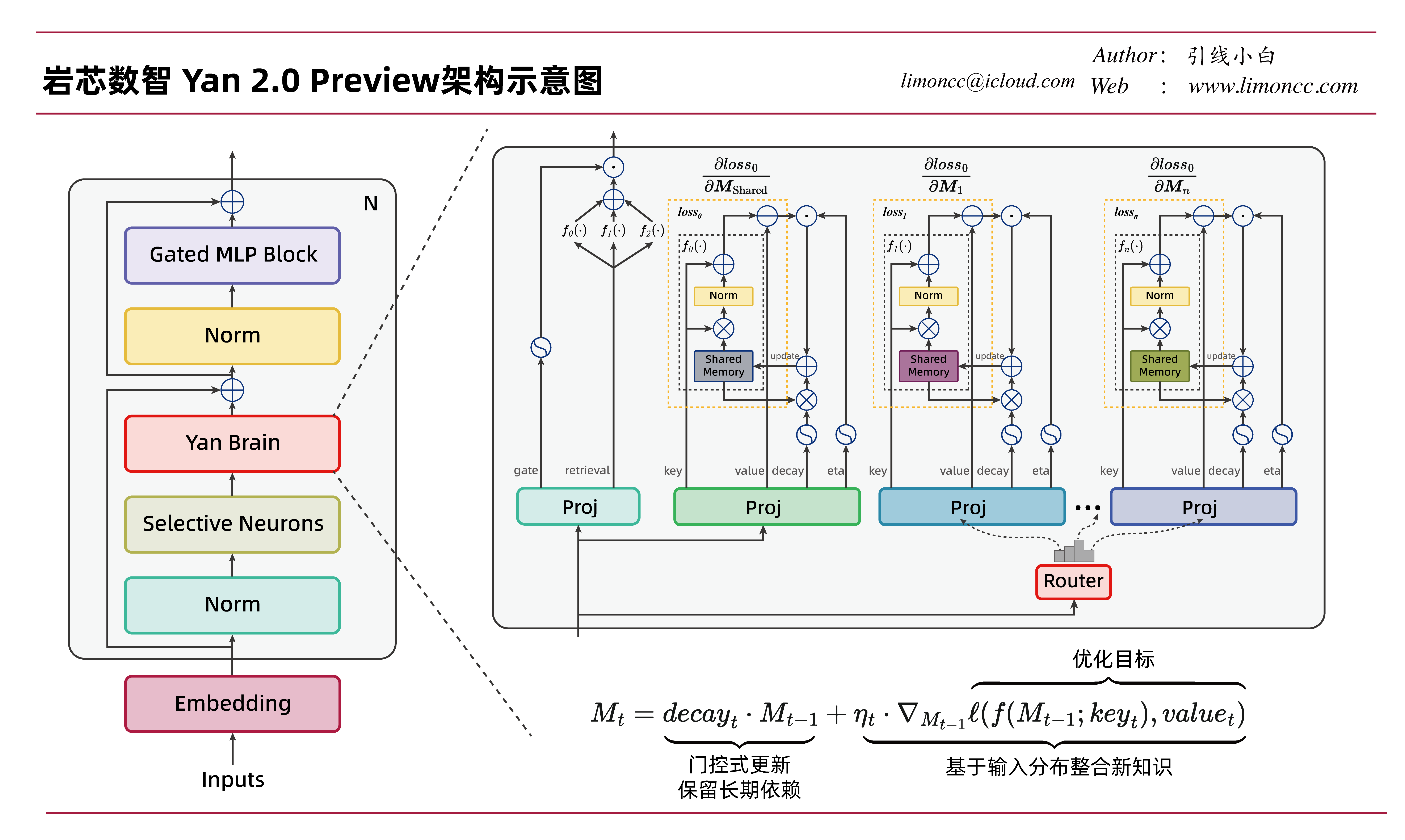
$$\begin{align}M_t = \underbrace{\textit{decay}_t\cdot M_{t-1}}_{门控式更新\quad 保留长期依赖}+ \underbrace{\eta_t \cdot \nabla_{M_{t-1}} \overbrace{\ell(f(M_{t-1};\textit{key}_t),\textit{value}_t)}^{优化目标}}_{基于输入分布整合新知识}
\end{align}$$
1、Yan 2.0 Preview中的函数 $f(\cdot)$其实就是记忆读取函数 $\textit{Memory}_{read}$。一般就 $f(\bm{M}_{t-1},\bm{k}_t)=\mathrm{Norm}(\bm{M}_{t-1}\bm{k}_t)+\bm{k}_t$, 这个加 $\bm{k}_t$的操作很让人疑惑。严重怀疑是图画错了。
2、记忆的目标函数是 $\ell(f(\bm{M}_{t-1},\bm{k}_t)-\bm{v}_t)$, $\ell(\cdot)$合理选择应该是 $\frac{1}{2}|\cdot|_F^2$, 也是就说 $\ell(f(\bm{M}_{t-1};\bm{k}_t),\bm{v}_t) =\frac{1}{2}|\mathrm{Norm}(\bm{M}_{t-1}\bm{k}_t)+\bm{k}_t-\bm{v}_t|_F^2$。加 $\bm{k}_t$ 的操作让人疑惑, $\bm{k}$ 和$\bm{v}$是不同的东西,做相减操作让人疑惑。
3、如果忽略那个令人疑惑的“加 $\bm{k}_t$”,和 $\eta_t$ 符号问题,记忆更新公式其实就是和RWKV差不多的操作,可以修正为
$$\begin{align}M_t = \textit{decay}_t\cdot M_{t-1}- \eta_t \cdot \nabla_{M_{t-1}}\ell(f(M_{t-1};\textit{key}_t),\textit{value}_t)
\end{align}$$
它是实际上带累计记忆衰减 $\textit{decay}_t = \bm{w}_t$的更新公式。如果令 $\ell(f(\bm{M}_{t-1};\bm{k}_t),\bm{v}_t) =\frac{1}{2}|\bm{M}_{t-1}\bm{k}_t-\bm{v}_t|_F^2$ 那么有
$$\begin{align}
\nabla_{\bm{M}_{t-1}} \ell(\bm{M}_{t-1}) = \bm{M}_{t-1}\bm{k}_t\bm{k}_t^\T - \bm{v}_t\bm{k}_t^\T
\end{align}$$
$$\begin{align}
\bm{M}_t = \bm{w}_t\odot\bm{M}_{t-1} - \bm{\eta}_t\odot(\bm{M}_{t-1}\bm{k}_t\bm{k}_t^\T - \bm{v}_t\bm{k}_t^\T)
=\bm{M}_{t-1}(\bm{w}_t - \bm{\eta}_t \odot \bm{k}_t\bm{k}_t^\T) + \bm{\eta}_t\odot\bm{v}_t\bm{k}_t^\T
\end{align}$$
4、对于MOE记忆模块
单纯图上看,存在一个共享记忆和并行的记忆模块,固定一个共享记忆加上动态选择2个并行的记忆。
$$
\begin{aligned}
\mathbf{O} =\sigma(\mathbf{W}_g \mathbf{x} + \mathbf{b}_g) \odot(f_0(\mathbf{x})+f_1(\mathbf{x})+f_2(\mathbf{x}))
\end{aligned}
$$
让了疑惑的是几个记忆直接先加 $f_0(\cdot) + f_1(\cdot) + f_2(\cdot)$后再门控。这个和MOE中常见的加权相加是不一样的。实际代码应该是加权更为合理。
$$
\begin{aligned}
\mathbf{O} =\sigma(\mathbf{W}_g \mathbf{x} + \mathbf{b}_g) \odot\left(\sum g_i(\bm{x})f_i(\mathbf{x}\right)
\end{aligned}
$$
总的来说 Yan 2.0 Preview架构图中体现的 基于线性注意力的MOE记忆机制还是一个可以参考的思路。
八、个人评述
从Hebb学习规则出发,穿过DeltaNet的对角加秩一变换、Titans的惊奇驱动更新,最终抵达Miras的统一优化框架。这条脉络揭示了一个深刻的范式转移:记忆正从一种启发式设计,演变为一个可被严格数学化的在线学习问题。
记忆本质的重新定义
传统的RNN将隐藏状态 $\bm{h}_t$ 视为一个被动的信息容器——它接收输入、混合旧状态,然后输出结果。这种视角下,记忆是副产物,而非设计目标。然而,DeltaNet的出现改变了这一切:它首次将状态更新明确建模为“在推理时执行梯度下降”,即 $\bm{S}_t = \bm{S}_{t-1} - \beta_t \nabla \ell(\bm{S}_{t-1})$。这意味着一一 记忆不再是被动存储,而是一个主动的、目标驱动的优化过程。
Miras框架将这一思想推向极致:它将所有记忆更新统一为在线凸优化的特例——每一个token的到来,都是对记忆参数$\bm{S}$发起的一次优化步骤,目标是在“保留旧知识”与“学习新信息”之间找到最优平衡。这一定义的深刻之处在于,它揭示了记忆与学习的同构性:记忆即是推理时的学习,学习即是训练时的记忆。
从惊奇到优化:Titans与Miras的互补
Titans的“惊奇驱动更新”具有强烈的认知科学直觉——人类确实更容易记住那些违反预期的事件。其将惊奇度定义为损失函数的梯度$\nabla \ell(\mathcal{M}_{t-1}; \bm{x}_t)$,并用动量项平滑惊奇信号,这与神经科学中“突触可塑性受惊奇度调节”的理论不谋而合。然而,Titans的设计仍停留在启发式层面:它没有明确回答“为什么梯度就是惊奇?”“动量衰减应该如何与任务结构关联?”
Miras弥补了这一缺憾。通过证明“学习-保留”视角与“跟随正则化引导者”(FTRL)的等价性,Miras为记忆更新提供了坚实的数学根基:任何有效的记忆更新规则,本质上都是在求解一个定义在历史数据流上的正则化经验风险最小化问题。Titans的惊奇梯度下降,恰好是当损失函数取瞬时预测误差、保留项取二次近端正则时的特例。RWKV-7的精细门控,则对应着在注意偏置中引入数据依赖的权重调制,以及在保留项中分别对“遗忘方向”和“写入方向”施加不同的惩罚结构。
机制设计的自由与约束
Miras框架最富启发性之处,在于它将记忆更新解耦为两个正交的设计维度——注意偏置(如何从新样本中学习)和保留机制(如何保护旧知识)。这一解耦意味着,未来的创新无需再在整体更新规则上做黑箱式的试错,而是可以针对性地分别改进这两个组件。
例如,在注意偏置上,可以超越简单的平方误差,引入对比损失、排序损失,甚至基于模型的预测不确定性自适应调整学习强度。在保留机制上,可以设计结构化的布雷格曼散度,使记忆遗忘不是均匀地衰减所有维度,而是基于信息论准则(如信息瓶颈)选择性地擦除冗余特征。这正是RWKV-7中$\mathrm{diag}(\bm{w}_t)$和定向遗忘项所暗示的方向。
更值得深思的是,元学习率$\eta_t, \alpha_t$的数据依赖化——让模型自己学会“何时该记住、何时该遗忘”——实际上是将记忆策略本身也纳入了学习范畴。这通向一个更宏大的愿景:元记忆,即关于记忆的记忆,关于如何调整记忆策略的记忆。这或许是通向通用人工智能的关键一步。
线性注意力的未尽之路
然而,我们也必须清醒地认识到当前框架的局限。无论是DeltaNet、RWKV-7还是Titans,其记忆都固化为一个固定尺寸的矩阵$\bm{S} \in \mathbb{R}^{d_v \times d_k}$。这种固定容量的记忆必然面临信息瓶颈:当序列长度远超$d_v \times d_k$时,旧信息必然被覆盖或衰减殆尽。
人类记忆的解决方案是层级化与结构化:我们不会将所有感知信息压缩进同一个工作记忆缓冲区,而是通过模式识别将信息抽象为概念,将概念组织为图式,将图式索引到长期记忆。这暗示下一代记忆架构可能需要:
- 多尺度记忆:短期工作记忆(高精度、快速更新)与长期语义记忆(低精度、慢速衰减)的协同
- 结构化寻址:不仅是基于$\bm{q} \cdot \bm{k}$相似度的内容寻址,还要支持基于关系、因果、层级的结构化检索
- 记忆巩固:像人类睡眠中的记忆重放机制,在低负载时段将工作记忆中的知识蒸馏进长期记忆
结语:作为认知范畴的记忆
将记忆视为在线优化,这一数学洞见所引发的涟漪远不止于架构设计。它迫使我们重新审视一系列根本问题:什么是遗忘?遗忘是最小化描述长度时的必然选择。什么是幻觉?幻觉是记忆读取时检索到了错误或过时的键值对。什么是理解?理解或许就是能够在记忆空间中为新信息找到合适的位置,使其既能被旧知识解释,又能修正旧知识的偏差。
塞缪尔·约翰逊说“记忆的真正艺术是注意力艺术”——在Transformer的语境下,注意力决定了哪些信息被读取;而在现代RNN的语境下,我们还需要追问:记忆的艺术不仅是注意力,更是关于在有限容量中如何取舍的优化艺术。Miras框架正是这一艺术的形式化宣言:记忆不是存储,而是决策;不是痕迹,而是策略;不是过去,而是为了未来而压缩的过去。
我们的旅程始于“什么是记忆”的追问,终于一个更精确的问题:“在资源受限的条件下,如何通过连续的在线决策,使过去的信息最大限度地服务于未来的预测?”这个问题没有终极答案,但每一次对它的逼近,都让机器离真正的记忆更近一步。
参考文献
[^1]: Schlag, I., Irie, K., & Schmidhuber, J. (2021, June 9). Linear Transformers Are Secretly Fast Weight Programmers. arXiv. https://doi.org/10.48550/arXiv.2102.11174ll
[^2]: Peng, B., Zhang, R., Goldstein, D., Alcaide, E., Du, X., Hou, H., et al. (2025, March 30). RWKV-7 “Goose” with Expressive Dynamic State Evolution. arXiv. https://doi.org/10.48550/arXiv.2503.14456
[^3]: Yang, S., Kautz, J., & Hatamizadeh, A. (2025, March 6). Gated Delta Networks: Improving Mamba2 with Delta Rule. arXiv. https://doi.org/10.48550/arXiv.2412.06464
[^4]: Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., et al. (2025, April 3). Learning to (Learn at Test Time): RNNs with Expressive Hidden States. arXiv. https://doi.org/10.48550/arXiv.2407.04620
[^5]: Behrouz, A., Zhong, P., & Mirrokni, V. (2024, December 31). Titans: Learning to Memorize at Test Time. arXiv. https://doi.org/10.48550/arXiv.2501.00663
[^6]: 新智元 https://zhuanlan.zhihu.com/p/1932500604414068556
[^7]: Behrouz, A., Razaviyayn, M., Zhong, P., & Mirrokni, V. (2025, April 17). It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization. arXiv. https://doi.org/10.48550/arXiv.2504.13173
[^8]: MiniMax, Li, A., Gong, B., Yang, B., Shan, B., Liu, C., et al. (2025, January 14). MiniMax-01: Scaling Foundation Models with Lightning Attention. arXiv. https://doi.org/10.48550/arXiv.2501.08313
[^9]:Jie, S., Tang, Y., Han, K., Li, Y., Tang, D., Deng, Z.-H., & Wang, Y. (n.d.). Mixture of lookup experts, 1–12.
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/1a40fb91b4777636/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Jul. 27, 2025). 《RNN的复兴02_什么是记忆》[Blog post]. Retrieved from https://www.limoncc.com/post/1a40fb91b4777636 |
| @online{limoncc-1a40fb91b4777636, title={RNN的复兴02_什么是记忆}, author={引线小白}, year={2025}, month={Jul}, date={27}, url={\url{https://www.limoncc.com/post/1a40fb91b4777636}}, } |